
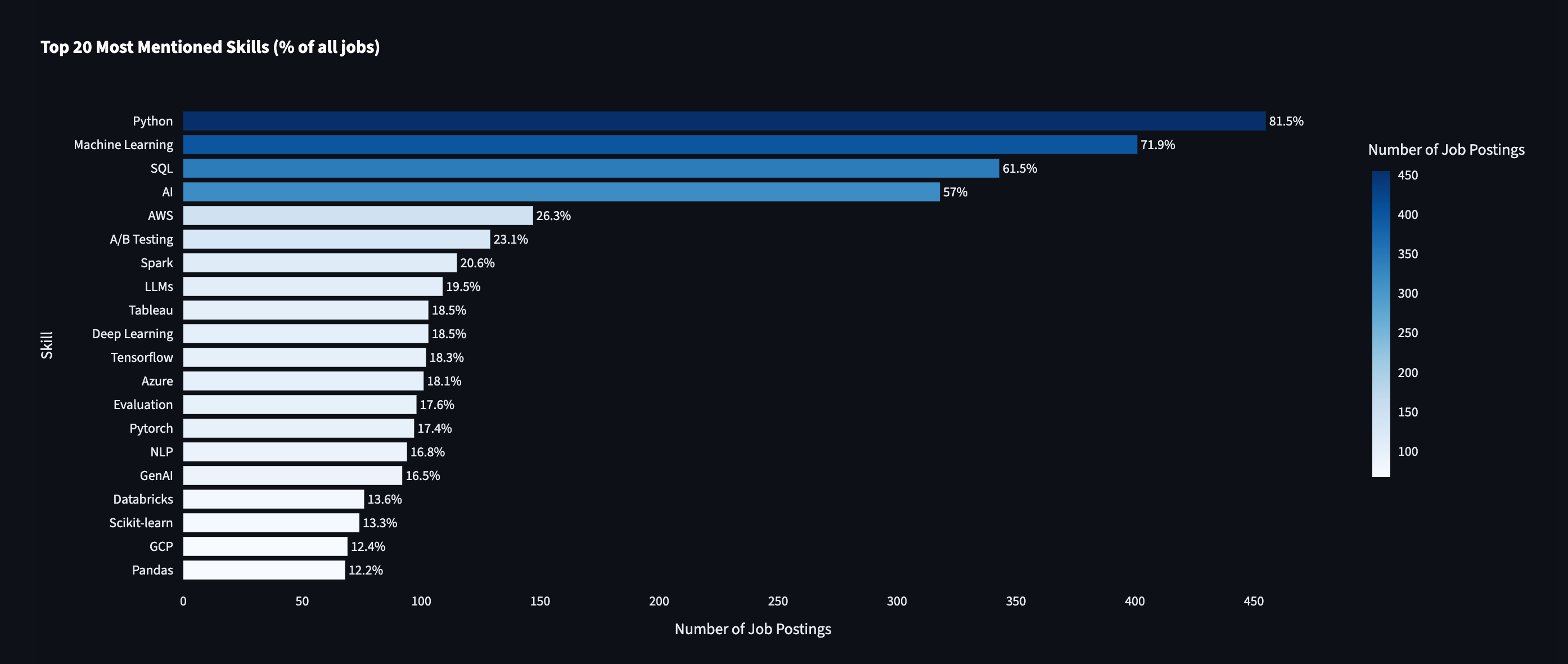
My 2026 Bets for Data Science (And 3 Things You Should Focus On)
Full analysis by a Senior Data Scientist experienced in building AI workflows

2025 was a year filled with exciting advancements, but also lots of uncertainty.
We saw AI truly disrupt the job market and the field itself, raising fundamental questions about the future of data science. At the same time, much of what we consumed online and in the news was wrapped in a thick layer of hype and misinformation.
No, data science is not “dying“. And no, AGI does not seem anywhere close, yet. But even though not every promise actually materialised, we did see a set of clear patterns emerge that are simply hard to ignore.
I know this, because I spent the better part of the year:
Studying the data & AI job market
Building AI workflows to automate and optimise my own work and future-proof my career
Attending conferences and having meaningful conversations across the industry
Running two data science and AI-focused newsletters that forced me to keep up with the news
So instead of making wild predictions, I want to share my bets for 2026, grounded in what we are already seeing today.
And at the end, I’ll share practical advice on what data scientists should focus on to accelerate their careers.
Bet #1: Agentic analytics will take center stage over traditional analytics
2026 will undoubtedly be the year when we start seeing these new types of data science workflows become normalized, where data scientists work alongside AI agents to automate and augment their work.
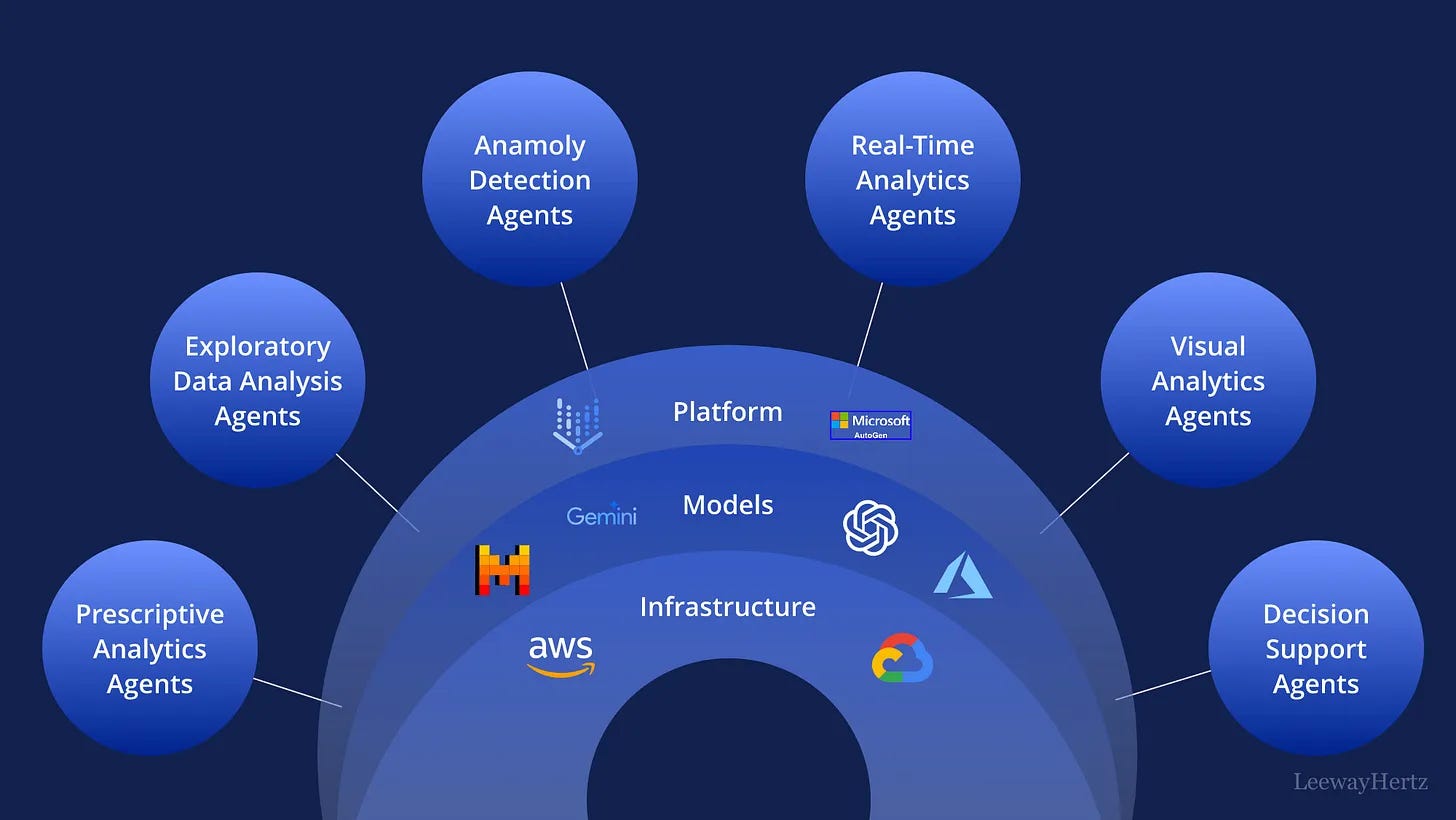
This goes beyond using tools like ChatGPT or Cursor to write code faster. Instead, we are talking about AI-powered workflows that can:
Explore data proactively
Detect patterns or anomalies
Run follow-up analyses
Make decisions with minimal human intervention
This is what the industry is calling Agentic Analytics.
To be clear, when I say agentic analytics will take center stage, I don’t mean that traditional analytics disappears. I mean that hand-written, step-by-step analysis stops being the default starting point, and instead becomes something we step into when judgment, nuance, or validation is required.
As a result, data scientists will start acting more as system designers and architects, letting these systems do much of the heavy lifting and getting involved primarily in the parts that require judgment and context, as well as presenting work in a way that actually drives decisions.
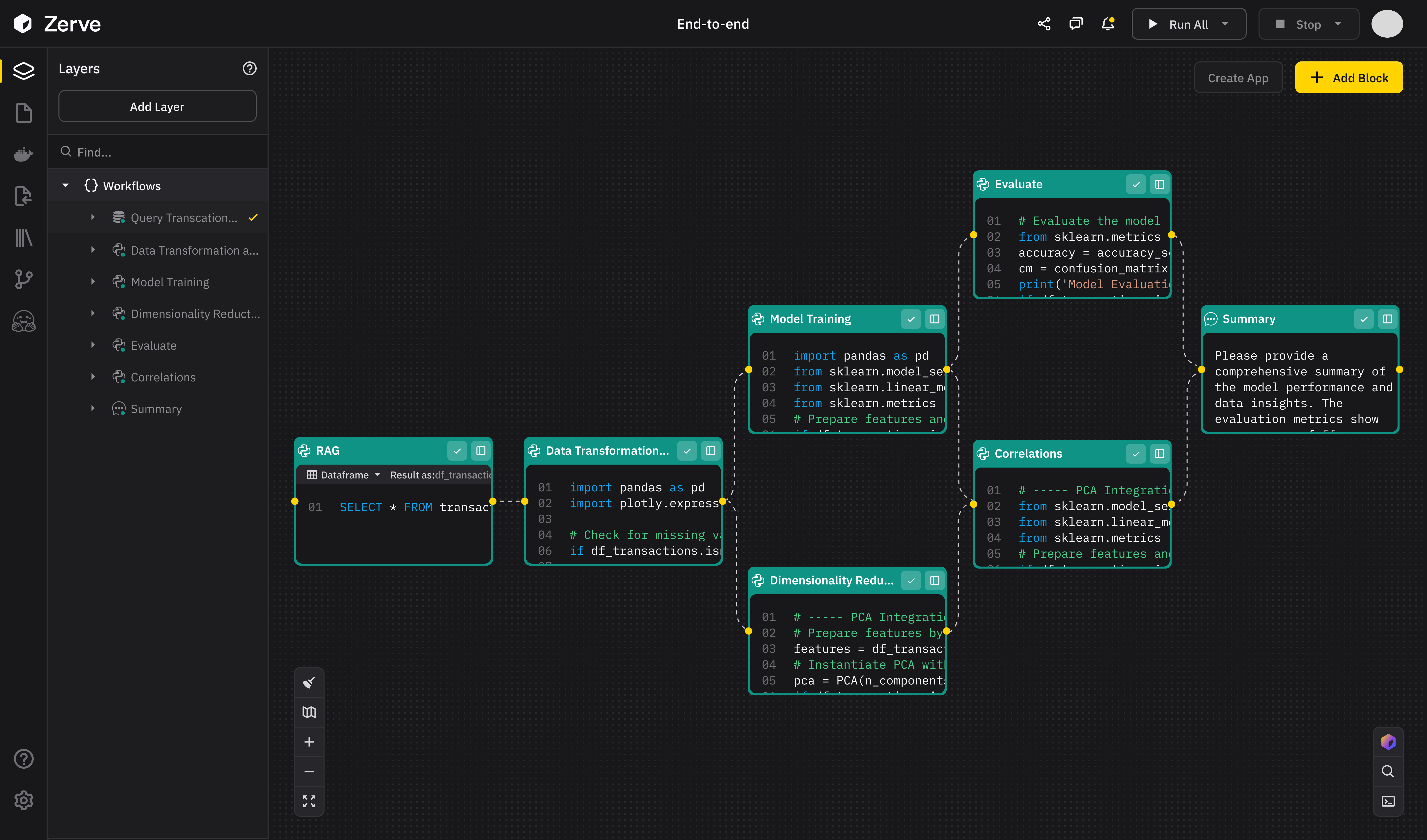
This will not happen all at once, though…
We will continue to see a selective group of data scientists lead the way and truly become 10x at what they do. This will impact both performance and the amount of value companies will expect a single data scientist to provide.
Towards the end of 2026, as we prepare to step into 2027, we will see a large wave of data scientists feeling the urgency to catch up. Improving their ability to think more like system designers, build these systems themselves, and adapt to the new tools already establishing themselves in the market.
Bet #2: We will witness the commoditization of the semantic layer
The modern data stack is no longer enough.
Companies will increasingly feel the need to move toward a combined data and AI stack.
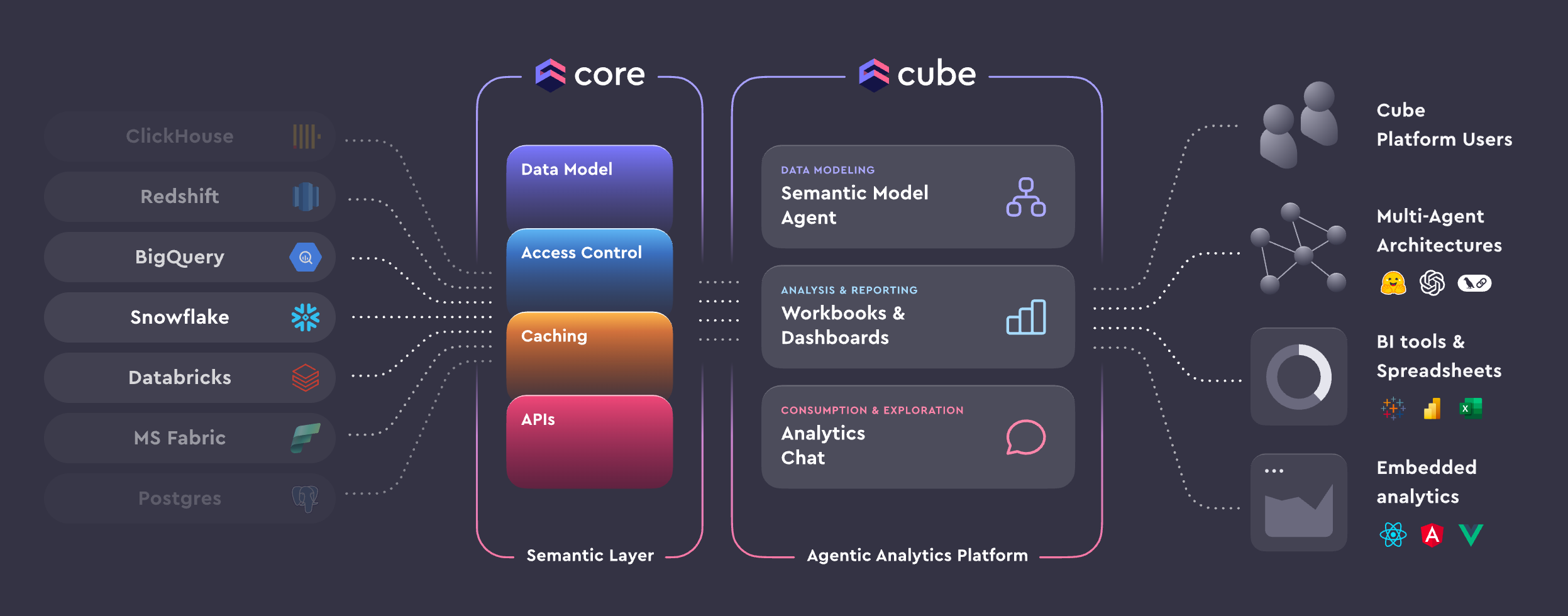
As a result, having a semantic layer will become a standard. Not as a nice-to-have, but as a prerequisite for keeping up with the next wave of agentic analytics.
This shift will highlight the value data engineers bring to the organization. But building and maintaining a semantic layer will not be a purely engineering problem. It will require the involvement and judgment of data scientists, especially when deciding how data should be interpreted, exposed, and used downstream.
For those organizations that have already adopted a semantic layer to support their Business Intelligence, we will see them optimize it with AI systems in mind. In particular, systems that allow non-technical stakeholders to “talk to their data” and request insights using natural language.
This will give way to a new definition of self-service analytics. One where the semantic layer becomes the shared foundation not just for dashboards, but for AI-driven decision-making across the company.
Bet #3: Foundation models will become central for tackling core data science problems more effectively
Instead of building a new model for every task, more teams will start reaching for foundation models as the starting point.
The reason is simple: they unify solutions. You move away from a fragmented landscape of narrowly trained models and toward shared representations that can be adapted across multiple use cases.
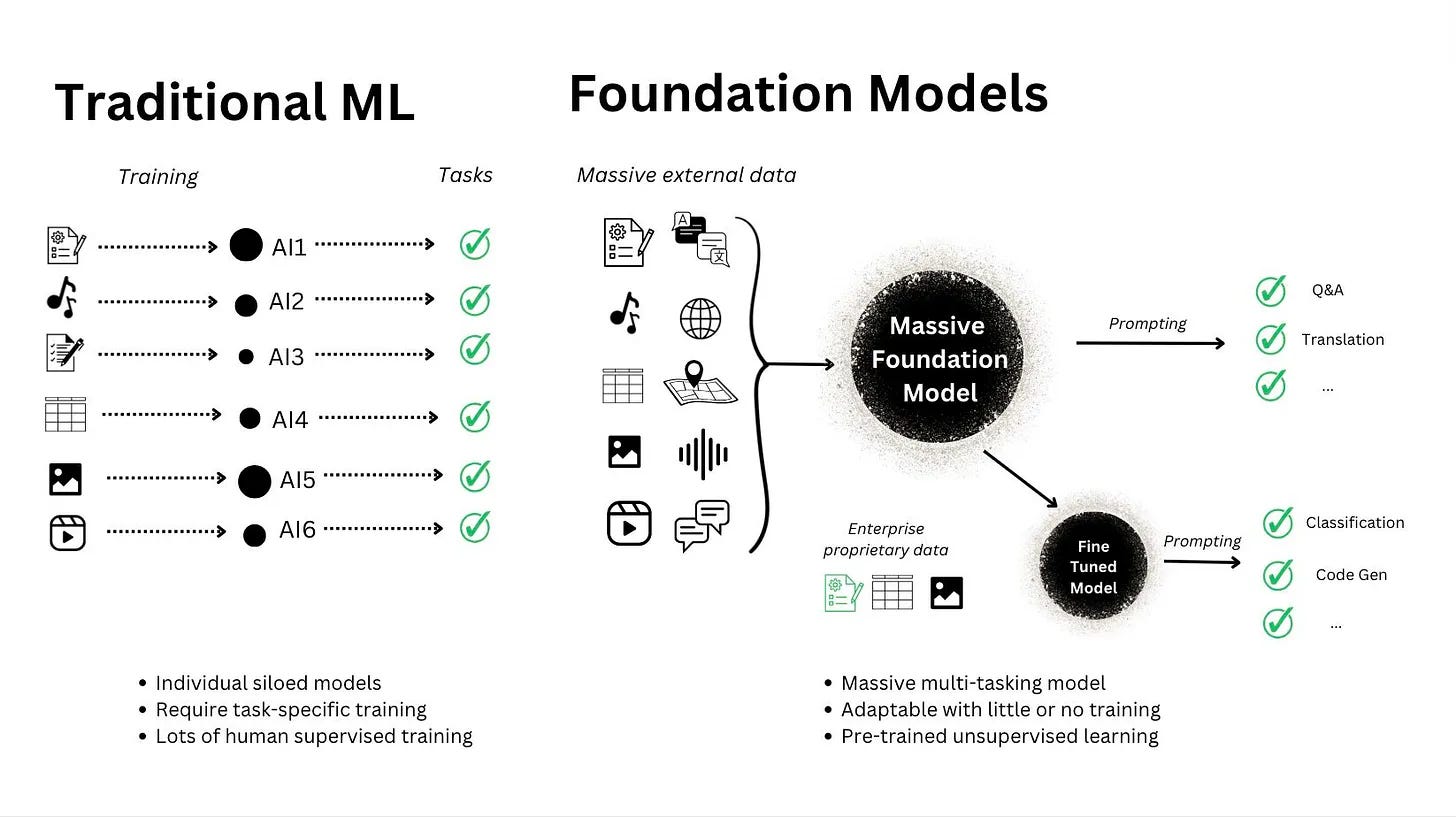
We are already seeing impressive progress in foundation models for anomaly detection and time-series forecasting. And while we will continue to see improvements there, I expect a lot of effort to go into foundation models for recommendation systems and ranking, along with other core areas where companies need models that generalize well and can be reused across products.
We have already seen signs of this direction from Netflix, where the industry is moving away from building isolated recommenders and toward more unified approaches.
What this means in practice is that the “modeling work” will change.
More data scientists will spend time training, adapting, and evaluating foundation models, and less time building task-specific models from scratch. The competitive advantage shifts toward understanding how to apply these foundations to real product problems, and how to ground them in your data, constraints, and success metrics.
Bet #4: The scope of data scientist roles will continue to widen
Over the past few years, we have seen the rise of more specialised roles: MLOps, AI Engineer, and similar titles are becoming more common. Data science, however, is not moving in the same direction.
Rather than becoming more specialised, the role is becoming more full-stack.
The reason is that data science sits at the intersection of business, engineering, and decision-making. That combination is simply hard to replace.
And now that AI has introduced new tools and techniques into the picture, we will see more data science roles pop up that require these types of responsibilities:
Build ML/AI systems end-to-end.
Build RAG systems to handle unstructured data
Train and work with foundation models
Handle guardrails and AI evaluations
By the way, I’ve done a deep analysis of the job market to understand what new AI tools and techniques are emerging for data science, and I will be sharing my full analysis next week, stay tuned.
And as the AI tools advance to facilitate the creation of these solutions, data scientists will evolve to think more like system designers. Designing, orchestrating, and maintaining their own workflows rather than working on isolated pieces.
Those who remain adaptable will thrive, while those who try to hold onto a narrowly defined version of the role will find it harder to keep up.
To clarify, I don’t believe specialised DS/Analytics roles will disappear. Product analytics, recommender systems, and other focused areas will continue to be in demand. But general data science roles will widen in scope, both by expectation and as a natural evolution for those who want to strengthen their skill set and remain future-proof
Bet #5: AI will turn non-technical stakeholders into entry-level data analysts
This shift is already underway.
Many non-technical stakeholders already have strong analytical instincts. What has been missing is not curiosity or problem framing, but the ability to handle the technical parts of the work. AI tools are increasingly filling that gap by taking care of tasks like querying data, writing code, and running basic analyses.
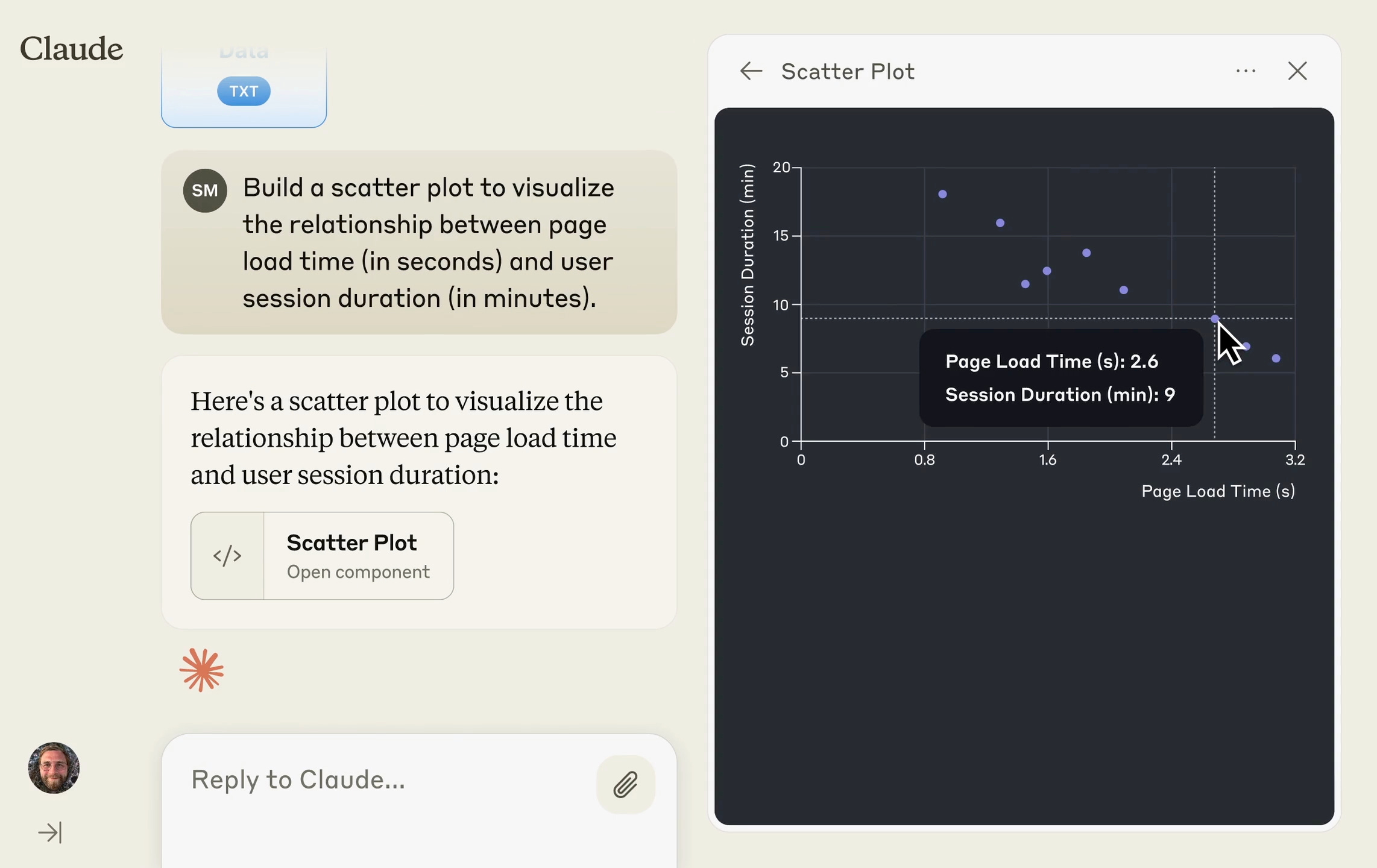
We have already seen this in product teams, where stakeholders are now able to build their own demos and proof of concepts. But it is not limited to product; we are starting to see the same pattern with data work. Stakeholders can upload CSVs or other structured data and have tools like ChatGPT or Claude analyze it for them, help them write basic SQL, or generate small scripts to answer concrete questions.
As a result, they rely less on specialized roles like data analysts for simple, exploratory work.
This trend is reinforced by two parallel shifts:
Everyday tools are becoming analytical tools: Excel, Google Sheets, and similar environments are rapidly gaining AI-powered features that make working with data more accessible. As these tools evolve, so do the analytical capabilities of the people using them.
BI tools are becoming conversational: With the rise of agentic analytics, non-technical users can increasingly talk to their data using natural language and get answers on demand.
Taken together, this doesn’t necessarily eliminate the need for data analysts, but it does raise the baseline. Many stakeholders will start operating at an entry-level analyst level, which will change both expectations and how analytical work is distributed across organizations.
If you want to get ahead, bring this with you into 2026
I know I mentioned quite a few changes coming into our field, and it might feel overwhelming to many of you, but at a high level, your strategy should be built around three areas, each helping you accelerate your career and stay relevant in the market:
Double down on human-centric skills
As more of the execution gets automated, skills like judgment, communication, and the ability to turn insights into decisions will be what truly differentiate strong data scientists.Focus on understanding how to build end-to-end systems
The biggest leverage will come from understanding how data, models, infrastructure, and decision-making fit together, not just from optimizing individual pieces.Don’t wait until it’s too late, start future-proofing your career today
The gap between those who adapt early and those who wait will widen faster than most people expect.
Here is my proven roadmap to build these skills in 2026
Everything I’ve shared so far reflects clear patterns already taking shape across the field and what they imply for data scientists going forward.
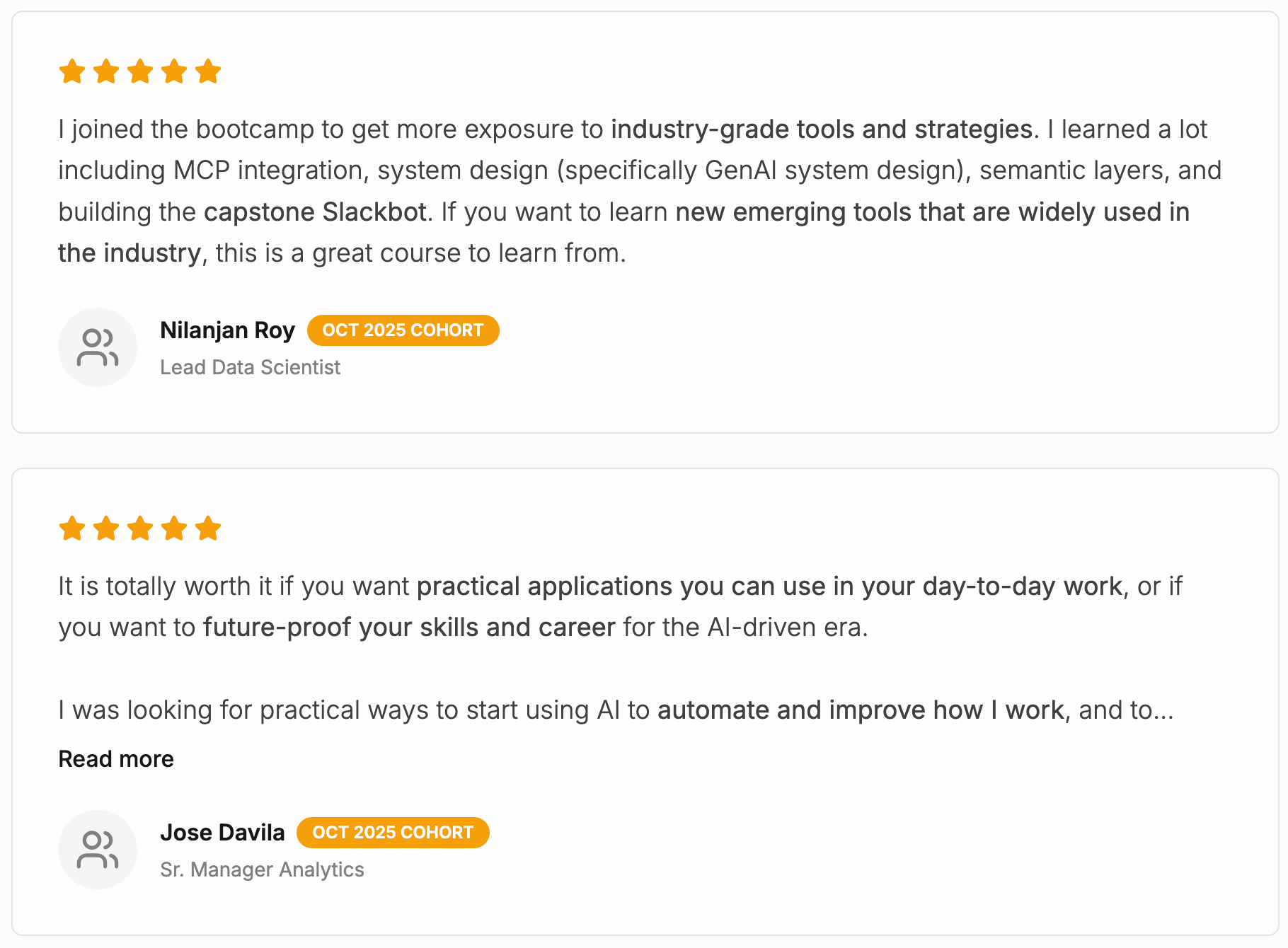
Over the past year, one way I’ve personally responded to these shifts is by building and refining a bootcamp focused on agentic analytics, AI workflows, and system-level thinking. It’s designed for data scientists who want to move beyond isolated analyses and start building end-to-end systems that actually scale their impact.

Last cohort, we welcomed 22 motivated students. This is what some of the alumni had to say:
Enrollment for the January 2026 cohort is now open, but seats are limited. Use the coupon code JAN26-25-ANDRES to receive 25% off (Only 10 left):
Keep in mind that if you miss this cohort, the next one won’t be available until mid-year.
Thank you for reading! I hope you found this article insightful. And share in the comments if you think there are any other trends I should’ve highlighted.
- Andres Vourakis
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!
With #1 and #5 I agree, but I am also skeptical that the final validation-bottleneck will rely on the actual analysts, because non technical stakeholders will eventually need someone to be held accountable. What do you think? Maybe I am grumpy and biased about this 😂