
What Are Foundation Models, and Why Should Data Scientists Care?
What the landscape looks like as we enter 2026

If you only associate foundation models with chatbots and image generation, you are missing the bigger picture.
While the spotlight for the past few years has mostly been on LLMs and diffusion models, there’s been a quiet shift happening in core data science workflows, too.
Let me break it all down for you in easy terms and help you understand what the road ahead looks like.
So, what are foundation models?
Think about traditional ML models, where each model is custom-built for specific tasks. Foundation models, on the contrary, are trained on massive, varied datasets so they can generalize.
You don’t start from scratch.
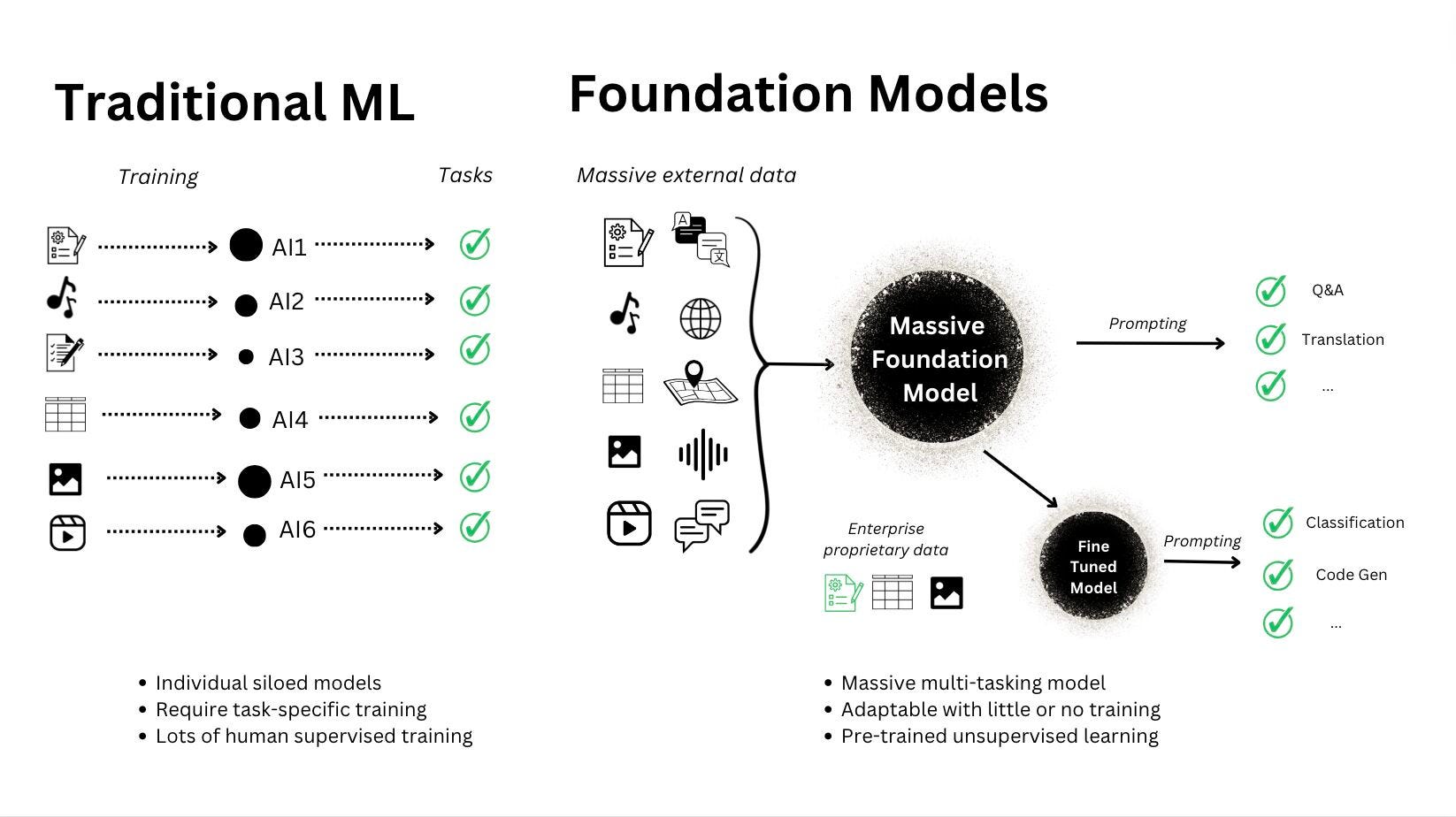
We’ve seen this change happen in NLP and computer vision. Now it’s spreading to core data science areas like time series, tabular prediction, anomaly detection, and recommendations.
Why does this matter for data scientists?
Because it shifts the way we build solutions.
Instead of training a separate model from scratch for each use case, these new models give us a starting point that’s already been trained on billions of datapoints across domains.
That means less fiddling with feature engineering, faster experimentation, and sometimes even better performance with fewer labeled samples.
Let me give you a concrete example…
Use Case: Netflix foundation model for recommendations
Earlier this year, Netflix shared how it is consolidating its recommendation stack with a foundation model trained on hundreds of billions of user interactions.
Traditionally, Netflix maintained many specialized models, each tuned for a specific surface: “Top Picks,” “Continue Watching,” “Trending Now,” and more. These models often used overlapping data but couldn’t share learnings easily, which slowed iteration and made scaling complex.
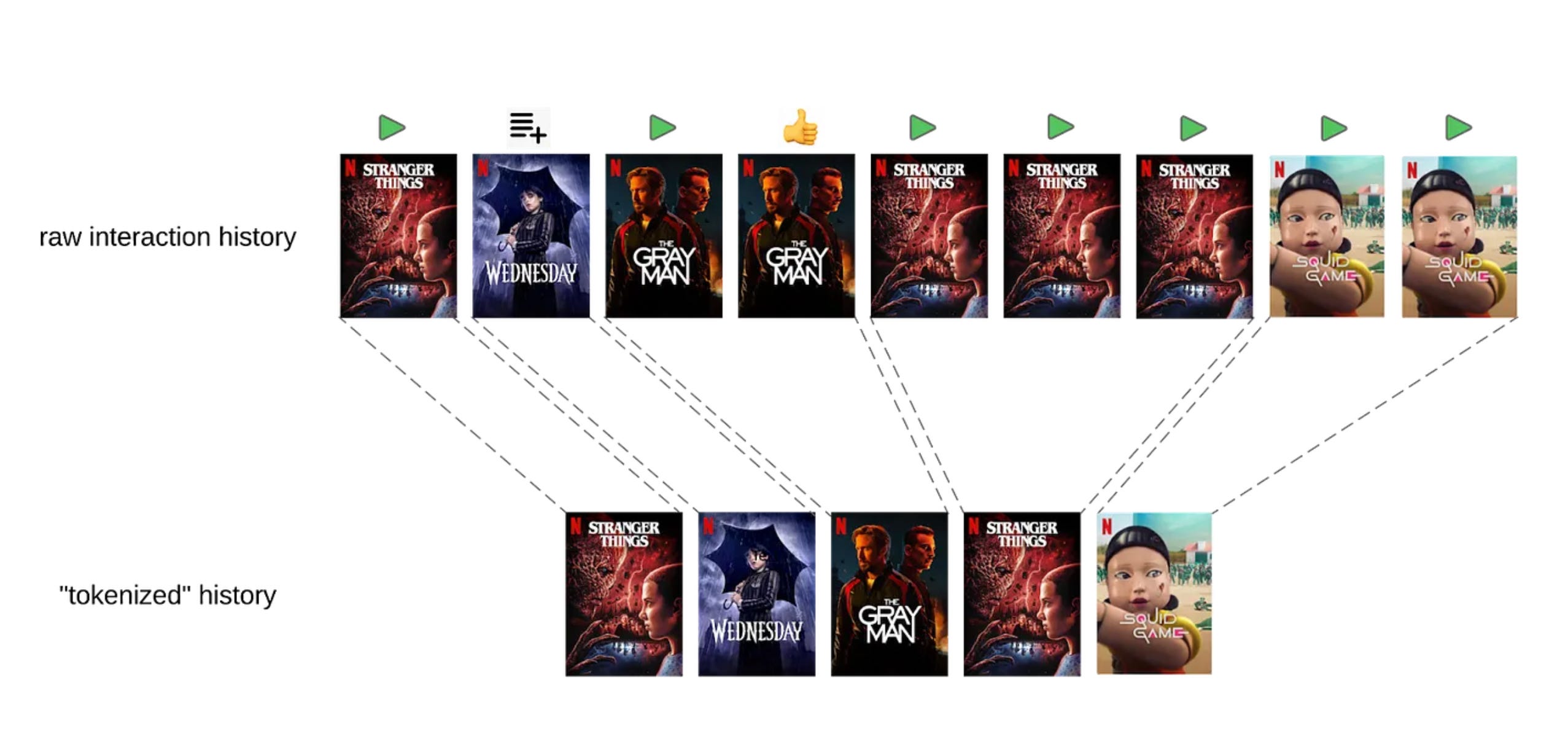
With their foundation model, Netflix takes a unified approach:
It learns user preferences across the full platform using a self-supervised next-token prediction setup, similar to GPT.
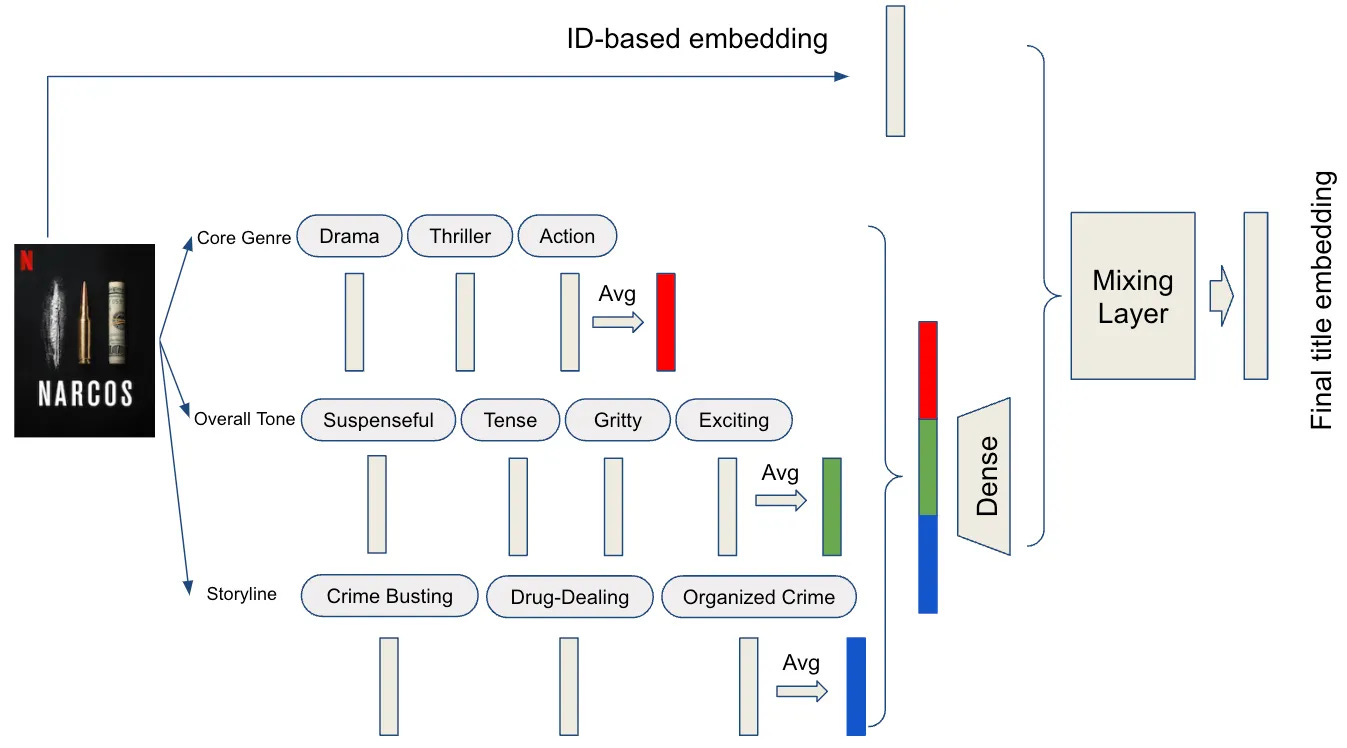
The model encodes entire interaction histories as sequences, using a custom tokenization process that preserves information like watch duration, device type, time of day, and more.
Sparse attention and sliding window sampling allow it to handle long user histories while keeping inference fast enough for real-time use.
Now, every product team can:
Generate user and content embeddings that encode long-term behavior and intent.
Use those embeddings for things like title-to-title similarity, personalized search, or candidate generation.
Fine-tune smaller heads for specific objectives (like ranking “Because you watched…”), without retraining the entire model.
This isn’t just about model consolidation, it also solves hard problems like cold-start. By mixing metadata-based and ID-based embeddings through an attention mechanism, the system can meaningfully represent new titles, even before anyone watches them.
Foundation models across domains (as of December 2025)
Here’s a quick overview of some notable models available today, at least the ones I was able to find:
What the current landscape tells us
From what I’ve found, most traction is happening in time series and sequential data. That makes sense since forecasting is painful to get right and even harder to scale across hundreds of products, SKUs, or sensors. Foundation models ease that pain.
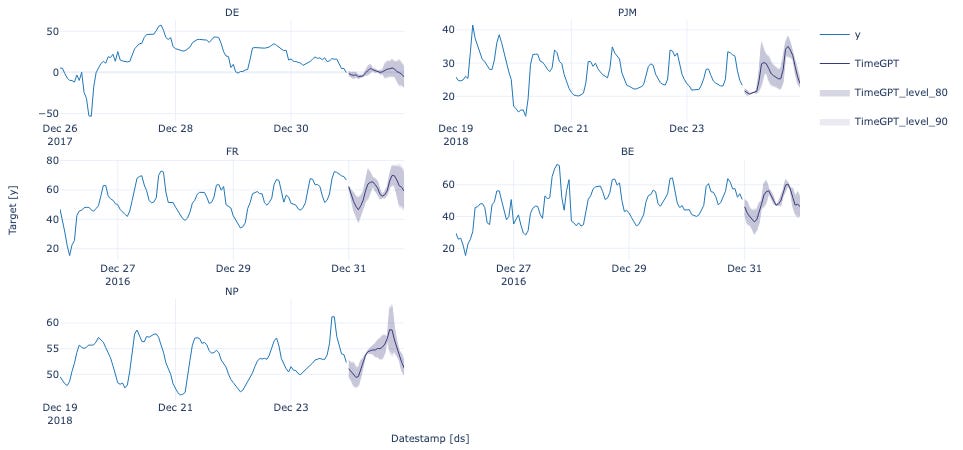
Other than that:
Tabular data is still underrepresented, but TabPFN is a promising start.
Recommendation systems are starting to get foundation-level treatment too, especially at large tech companies with massive interaction logs.
What’s missing? Broad adoption. Many of these models are still in early-access APIs or internal use only. But the momentum is clear.
Final thoughts
You don’t need to bet your entire pipeline on these models, unless you’ve got the perfect use case, but they’re absolutely worth getting familiar with:
Test TimeGPT or TimesFM via their APIs or SDKs
Try TabPFN on a small tabular dataset
Follow open-source projects like MOMENT or Moirai for broader use cases
Foundation models are moving fast. Staying close to them now will pay off later.
A couple of other great resources:
🚀 Ready to take the next step? Build real AI workflows and sharpen the skills that keep data scientists ahead.
💼 Job searching? Applio helps your resume stand out and land more interviews.
🤖 Struggling to keep up with AI/ML? Neural Pulse is a 5-minute, human-curated newsletter delivering the best in AI, ML, and data science.
Thank you for reading! I hope this gave you a clearer view of modern solutions to core data science problems.
- Andres Vourakis
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!
Great read 🙏😊
What I find interesting is that this is how AI enters real world economic impact. It is NASA training foundational models on launch optimizations. It isn’t through the agents building