
When Is It Actually a RAG Problem?
A decision framework for data scientists

Over the past few months, I’ve talked to a lot of data scientists who are trying to figure out RAG.
Not building with it yet, just trying to figure out if they should.
They’ve seen it in job postings. They’ve read a few articles. They have a use case in mind at work. And the question they keep coming back to is some version of:
Is this actually a RAG problem, or am I reaching for the wrong thing?
It’s a fair question. And it’s harder to answer than it sounds, because RAG doesn’t sit alone. It shares space with two other patterns that show up in the same conversations and sound like they do the same job: MCP and semantic layers.
So here's the answer I've been giving in those conversations. By the end of this article, you'll know exactly when RAG is the right call, and when something else fits better.
Here’s what we’ll cover
Why RAG is suddenly showing up everywhere
What RAG actually is (skim if you already know)
The four times a “RAG problem” isn’t one
When RAG actually makes sense
Where these patterns actually work together
📌 Resource: Building your first RAG system
Why RAG is having a moment
Every company I talk to has the same split.
Their structured data is handled. Dashboards, SQL, the warehouse, it’s all fine.
People know how to ask questions of it. But the moment a question depends on unstructured data: the PDFs, the support tickets, the internal docs, the Confluence pages, the meeting transcripts. There’s no good way to get at it; it just sits there.
That’s the gap RAG fills.
And it’s starting to show up more and more in the job market. After analysing 4K+ data scientist job postings, RAG appeared as the top-4 AI skill in demand.
It’s not the most common skill on the list yet, but a year ago, it was barely there, and it keeps gaining more demand.
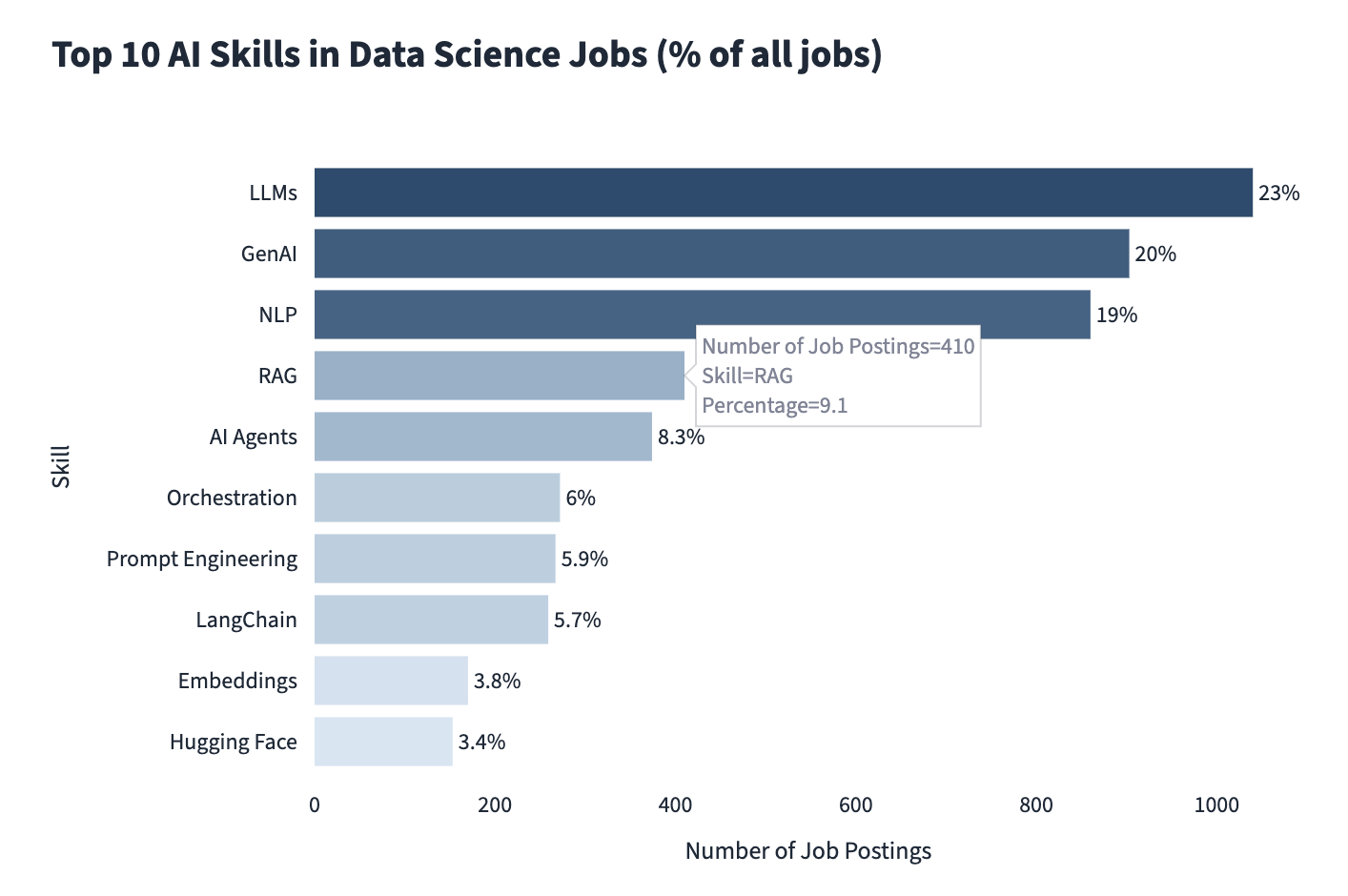
So yes, RAG is worth learning.
But that’s the easy part. The harder part is knowing when to use it.
What RAG actually is
Skim if you already know.
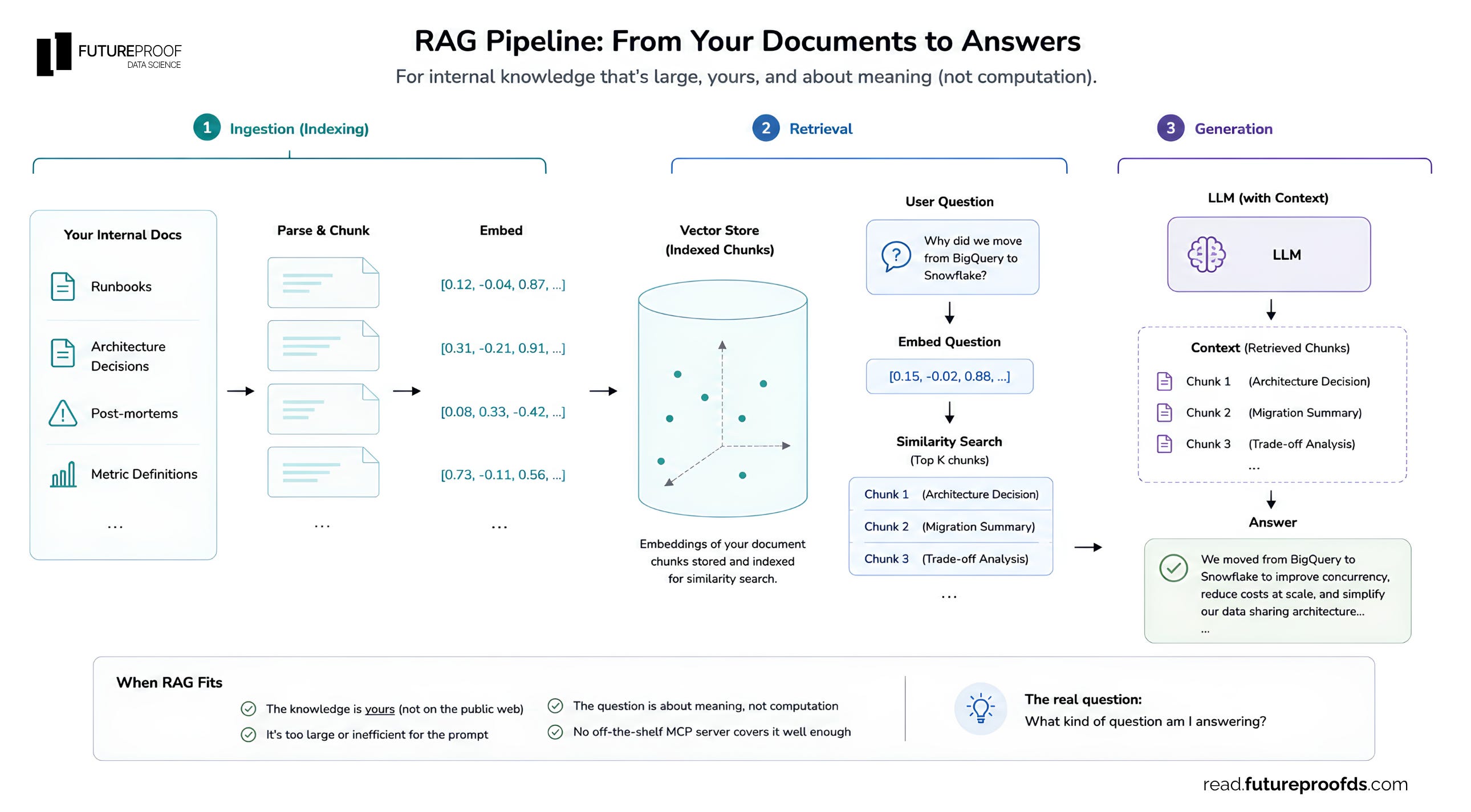
RAG (Retrieval-Augmented Generation) is a pattern where you retrieve relevant content from your own data and pass it into a model so the answer comes from that, not from the model’s training memory.
Three phases:
Ingestion (done once, ahead of time): your documents get parsed, chunked, embedded, and stored.
Retrieval (done per query): the user’s question gets embedded, and you search the store for similar chunks.
Generation: the model gets the question plus the retrieved chunks, and produces an answer grounded in them.
The key shift: SQL retrieves by literal match. RAG retrieves by meaning. That’s what makes it useful for text.
Why “should I use RAG?” is a hard question
The reason this question trips people up isn’t RAG itself. It’s that RAG isn’t the only thing in the room.
Two other patterns show up in the same conversations and sound like they do the same job:
MCP (Model Context Protocol): a standard for connecting models to existing systems (Notion, Confluence, Slack, Google Drive, internal APIs). Retrieval is involved, but you don’t build it. You inherit it from whoever wrote the MCP server.
Semantic layers: a modeling layer over your structured data that defines business logic, metrics, and dimensions in one place. Not retrieval in the same sense as RAG, but it's how AI systems (and BI tools, and chatbots) get reliable access to your metrics.
These aren’t apples-to-apples with RAG.
MCP is a delivery mechanism. A semantic layer is a modeling layer. RAG is a retrieval pattern. But they all show up the moment someone says “I want AI on top of my data”, and from the outside, they sound interchangeable.
So before reaching for RAG, it’s worth asking: am I sure this is what I need?
Here's how I think about it: four cases where something else fits better, and one where RAG is the right call.
Case 1: “Can’t I just dump everything into the prompt now?”
What you actually need: in most cases, still retrieval.
This is the argument you’ve probably seen on X. Context windows used to be small, so you had to retrieve the relevant chunks before sending them to the model. Now that windows are at 1M+ tokens, why retrieve at all? Just load the whole knowledge base into the prompt every time.
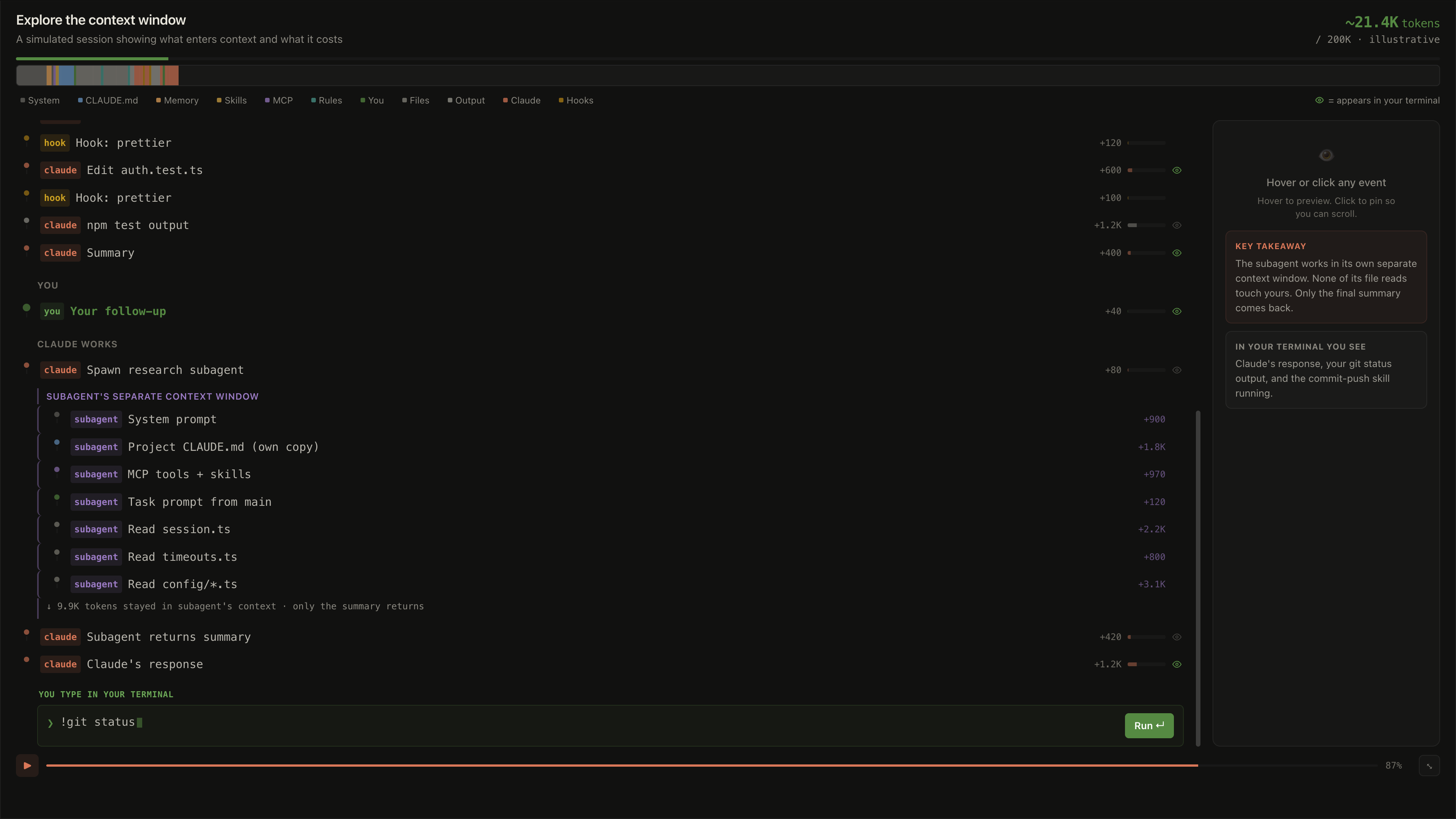
For a small, slow-changing corpus, sometimes yes. If your “knowledge base” is your team’s 8 metric definitions and 3 architecture decision docs, a cached system prompt covers it. No vector store, no chunking, no eval loop.
But for most real systems, no. A few reasons:
Cost scales with tokens loaded. Even with caching, you pay to load context. Stuffing 200K tokens into every query gets expensive fast at scale.
“Lost in the middle” is real. Models read the start and end of long contexts well, and the middle much worse. A 1M context window doesn’t give you 1M tokens of equally useful attention.
Latency. Long-context queries are noticeably slower than retrieval-style ones.
Freshness. A cached context doesn’t update on its own. Anything that changes often needs to be reloaded.
The honest framing: bigger context windows didn’t kill RAG, they raised the floor for when you need it. If your corpus is small and stable, skip retrieval. If it’s large, fast-changing, or queried at scale, you still need RAG.
Case 2: The answer lives on the public web
What you actually need: a web search tool.
You don’t want to be in the business of indexing the internet, and you don’t need to be.
If you’re asking “how does this new Python library handle async?” or “what did the latest BLS report say about wage growth?”, you want web search, not RAG.
I know this might seem basic to some of you, but it's worth clarifying.
When people hear "extend the LLM's knowledge base," they often jump straight to RAG. But if the knowledge they need is public, the tooling already exists. If you're building, there's Tavily and similar APIs. If you're using existing AI tools (Claude, ChatGPT, Perplexity), web search is already baked in.
Case 3: The question is really a SQL question
What you actually need: a semantic layer.
This is the one where I see the most confusion.
If the question is “how many sign-ups last quarter?” or “average order value by region”, that’s SQL, not RAG. RAG can’t compute averages over your sales table. It can find a paragraph that mentions sign-ups, but it can’t sum a column.
If your stakeholders want natural-language access to those numbers, what you actually want is a semantic layer. Something like Cube, dbt’s semantic layer, or LookML. It defines your metrics once and lets an AI system (or a BI tool, or a chatbot) translate questions into the right query against your data.
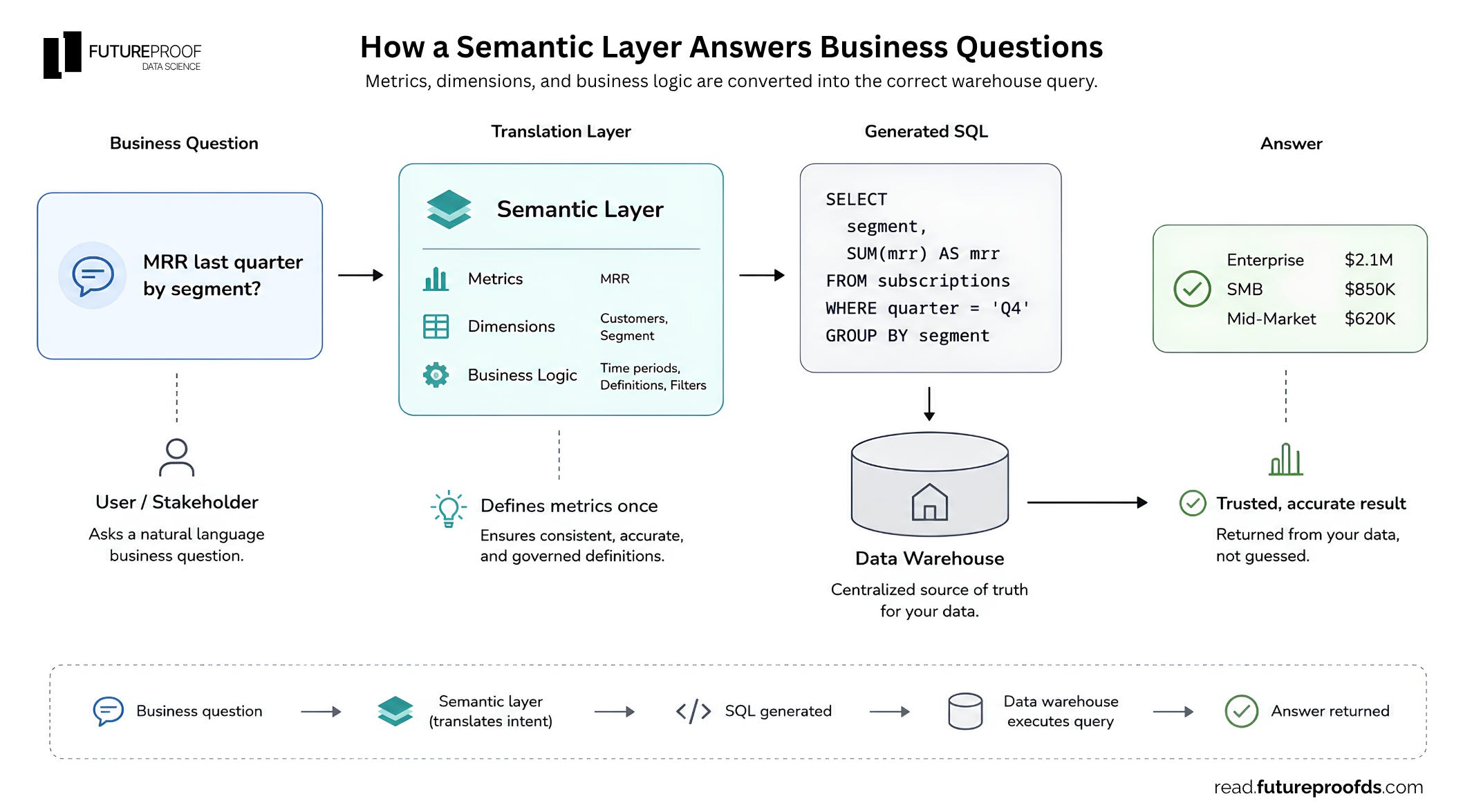
A RAG pipeline pointed at a data warehouse export will happily return a number that looks plausible and is actually wrong. That number doesn’t stay in your notebook, it ends up in a deck.
Case 4: Someone already built the retrieval for you
What you actually need: an MCP server.
If your knowledge lives in Notion, Confluence, Linear, or a similar system, check whether there’s already an MCP server for it before you build anything. If there is, you’ll ship grounded answers faster than you can spec out a chunking strategy.
Imagine you’re in Claude Code working on an analysis, and you need to understand the business context around a feature your team shipped last quarter. The PRD lives in Confluence. With the Confluence MCP server connected, Claude can pull the PRD directly during the analysis. You didn’t build a RAG pipeline. You didn’t chunk anything. The retrieval happens for you.
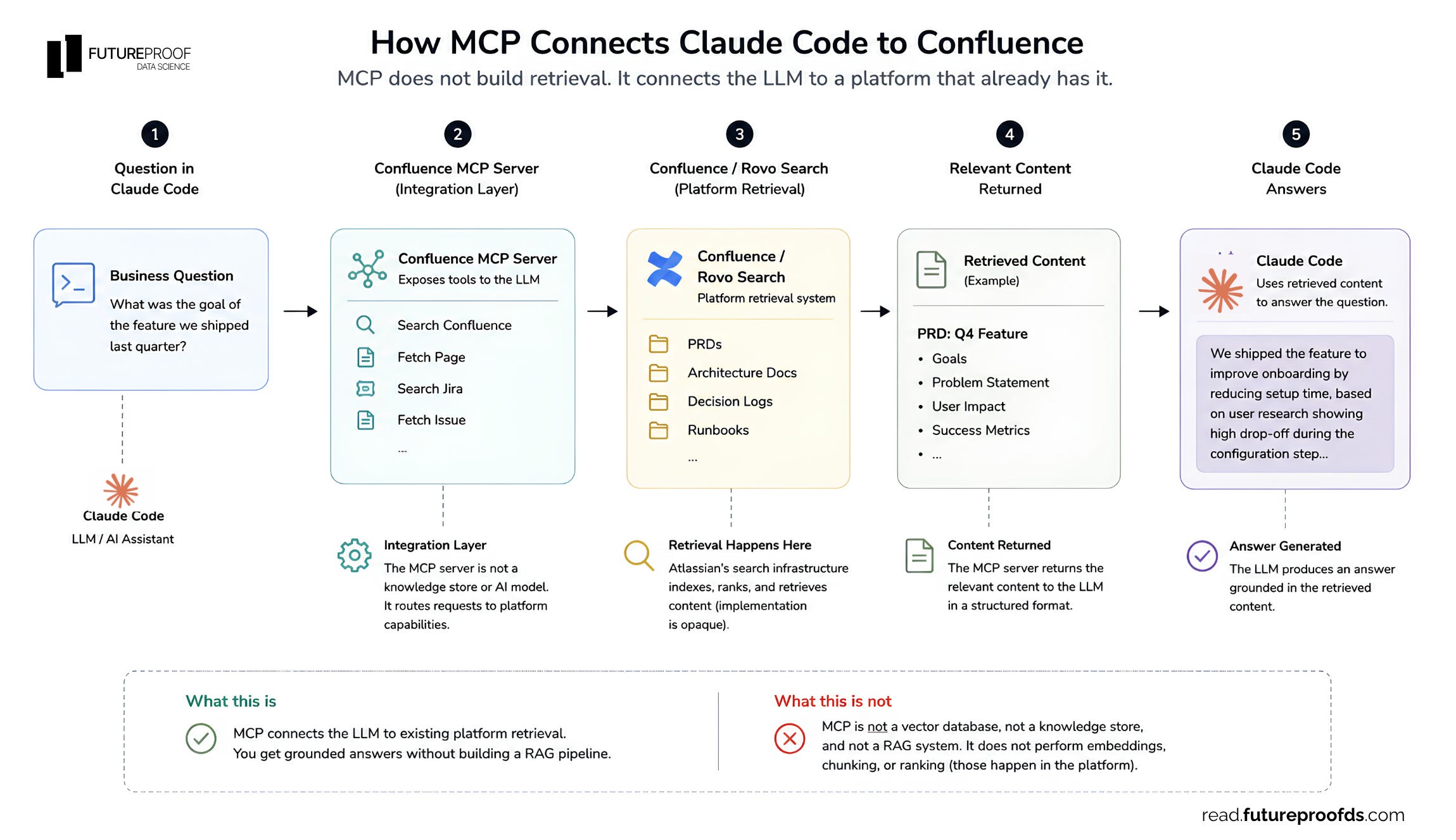
You do inherit whatever retrieval choices the server makes (chunking, ranking, filtering). For some use cases, you’ll outgrow that and need your own pipeline. But starting with MCP is almost always the cheaper first move.
The case where RAG actually fits
A body of text the model needs to read before it can answer well, where:
The knowledge is yours (not on the public web)
It’s too large or inefficient for the prompt
The question is about meaning, not computation
No off-the-shelf MCP server covers it well enough
Think of an assistant that answers questions from your team’s internal documentation: runbooks, architecture decisions, post-mortems, metric definitions written up in long-form.
A new hire asks, “why did we move from BigQuery to Snowflake?” and the system surfaces the right architecture decision doc.
That’s a real RAG case. The knowledge is yours, it’s text-heavy, it’s too large for a prompt, and the question is about meaning, not a number.
The first question is never “should I use RAG?” It’s “what kind of question am I answering?”
The quick-reference version
If you only remember one thing from this article, remember this table.

Four out of five times, RAG isn't the answer. That's the part most people miss.
Where these patterns actually work together
One more thing…
These patterns aren’t competing. The best AI systems use all three.
Imagine a “talk-to-your-data” Slackbot at a real company:
A semantic layer lets the system answer “how many enterprise sign-ups last quarter?” by translating to SQL against a defined metric.
An MCP server lets it pull the latest ticket from Linear or the latest doc edit from Notion.
A RAG pipeline lets it surface the right paragraph from your internal playbook when someone asks “what’s our refund policy for annual plans?”
Same system. Three retrieval patterns. Each owns the questions it’s actually good at.
The skill that’s getting harder to find isn’t building any one of these. It’s knowing which pattern owns which question, and then composing them into a system that picks the right tool for the job.
Want to build your first RAG system?
RAG is showing up in more data scientist job postings every quarter for a reason.
The unstructured side of every business is huge, and once you can build retrieval over it, you become the person on the team who handles the half of the data that everyone else can't.
This is why I put together a RAG crash course for data professionals, where you'll build your first RAG system end-to-end, including evaluation.
And I'm giving it away free to anyone who enrolls in the upcoming cohort of my AI Workflows Bootcamp, which starts June 12.
You don't want to miss this. The bootcamp teaches you to leverage AI day-to-day and build systems with real design judgment. The RAG course adds the unstructured side. Together, that's the toolkit most data scientists are still missing.
A couple of other great resources:
🚀 Ready to take the next step? Get my free workshop on agentic analytics for data scientists.
🎥 Want to follow along on YouTube? I just launched a channel for data scientists. Subscribe, first video drops soon.
Thank you for reading! I hope you find this guide useful.
- Andres Vourakis
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!