
Testing the Limits of PandasAI (Part 2): Building a Semantic Layer For Better Insights
Helping PandasAI understand your business context

This is part 2 of the “Testing the Limits of PandasAI“ series. If you haven’t read [Part 1], it breaks down how PandasAI works under the hood and explores its default behavior, strengths, and limitations. It lays the groundwork for everything we build on here.
Context is king
Whether you are talking to a human or an LLM, the rule is the same: the more relevant background you provide, the better the answer.
The problem is that when talking to LLMs, even if you write detailed and well-formatted prompts, you’ll still run into limitations when trying to make the output truly useful for your specific use case.
So it’s no wonder the term “context engineering” has become so popular lately.
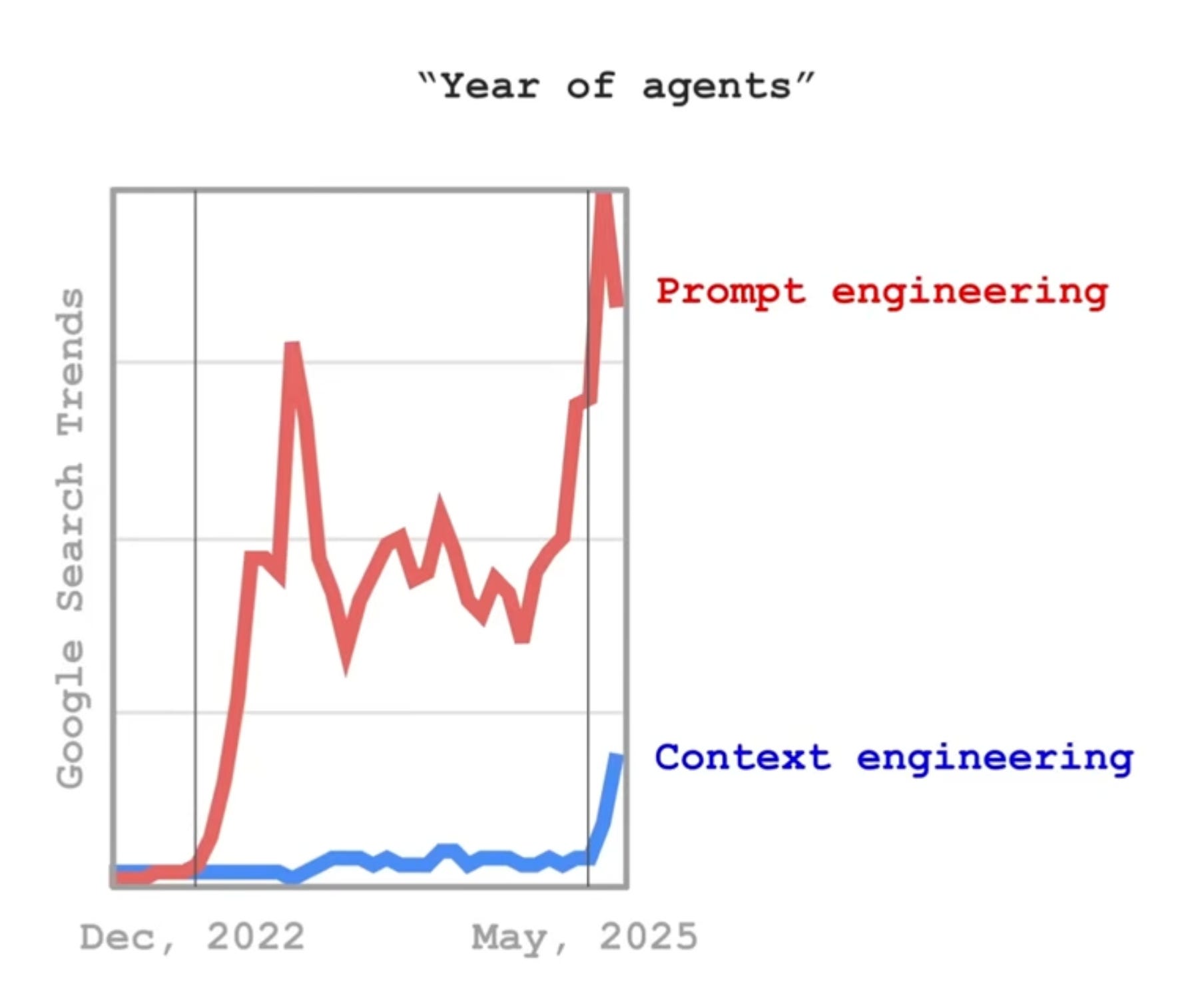
Luckily for us, the developers behind PandasAI had this in mind when developing v3.
With this new version, we have the ability to give the agent a clearer view of our tables and concepts before it even writes any code.
We can create a semantic layer that maps field names to real meanings, standardizes terms, and adds short descriptors that the model can use while generating pandas code
So that is exactly what I’ll break down for you in this article.
Trust me, with this simple change, you’ll start getting true value from PandasAI.
What PandasAI knows, by default
In part 1, we took a peek into how PandasAI works under the hood every time you ask it a question like “What is the average revenue?“.
We saw that when it builds a prompt for the LLM, it doesn’t just include your question but also some additional context that it gathers by default.
In short, PandasAI collects this from your data:
Column names
A few preview rows
Metadata from your DataFrame
and then insert them along with your question into a template for the LLM.
Although this is a huge step forward in the right direction, it still leaves room for the LLM to make assumptions about what each column means and how to transform them correctly.
And well, if on top of that you are also using cryptic field names (shame on you btw), then it’s just a pure guessing game for the LLM.
This is where a semantic layer comes in.
The solution: A Semantic Layer
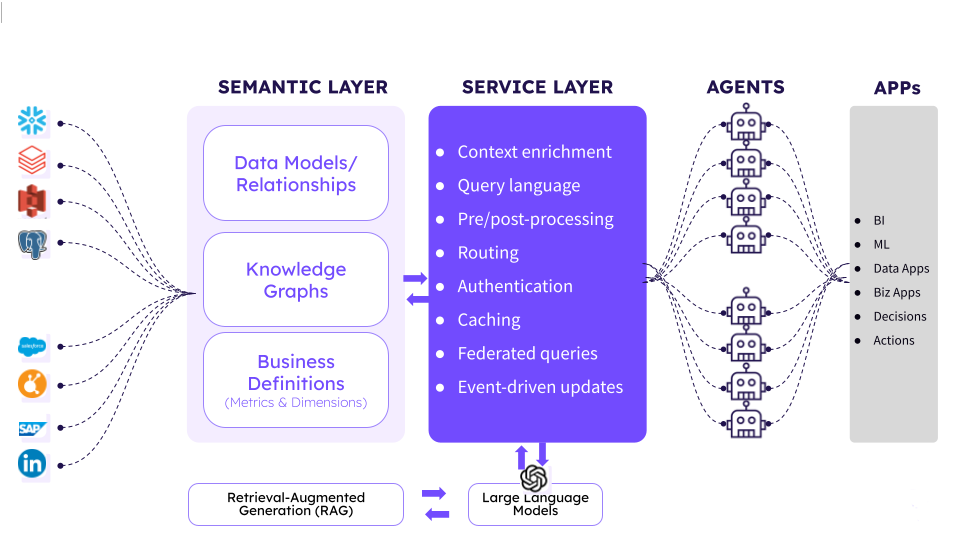
In simple terms, a semantic layer is a structured description of your data. Instead of relying on raw column names, you explicitly tell the model:
What each field represents
What type of data it contains (string, integer, float, date, etc.)
Any aliases or business-friendly labels
Optional rules for grouping, filtering, or transforming values
Think of it as metadata that sits on top of your DataFrame, guiding the LLM toward the right interpretation.
💡 It’s similar to what tools like dbt or LookML do in analytics engineering: creating a shared vocabulary so both humans and machines can reason about the data consistently.
How do you build one in PandasAI?
The simplest way to define a semantic layer schema is to use the create method:
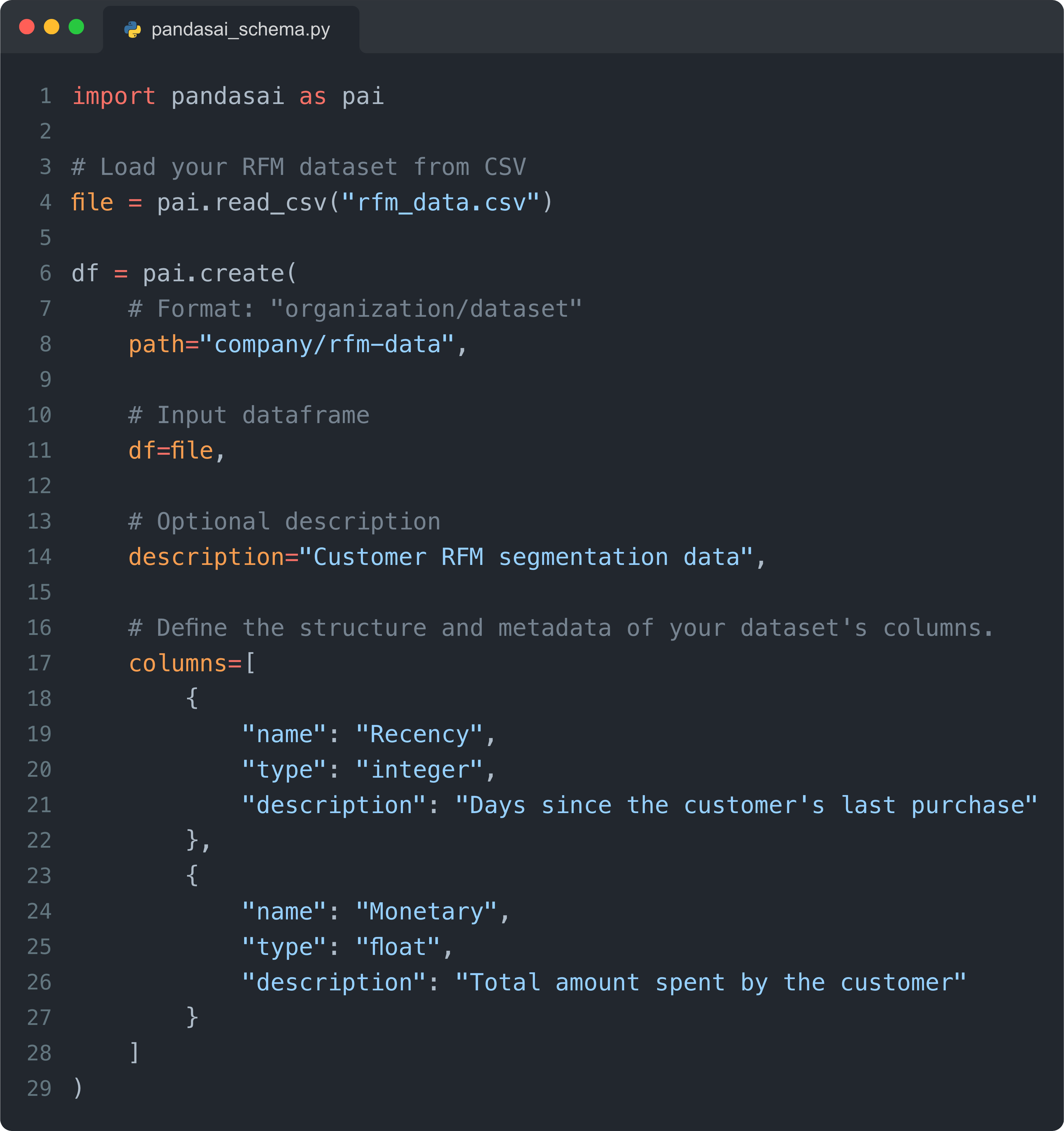
As you can see, it’s actually very simple. But manually defining columns is fine for a demo or even for quick EDA, not for working in production.
So let’s explore how we can make this setup production-ready.
📦 Making a production-ready Semantic Layer
In practice, your schema already lives in your data warehouse, and if you're planning to use PandasAI in real workflows, you'll want a repeatable, automated way to structure and load that schema into PandasAI.
Here is my recommendation to do it right:
1. Extract the schema from your warehouse
Use your warehouse’s information_schema (or introspect it through a client like dbt or SQLAlchemy) to pull column names and types.
This gives you the raw metadata: columns, types, and optional descriptions, all from your actual source of truth.
2. Map your column types to PandasAI’s format
PandasAI expects each column to have a simplified type: string, integer, float, datetime, or boolean. So you’ll likely need to translate from your default warehouse’s types.
For example, this is roughly what it would look like for a BigQuery schema:
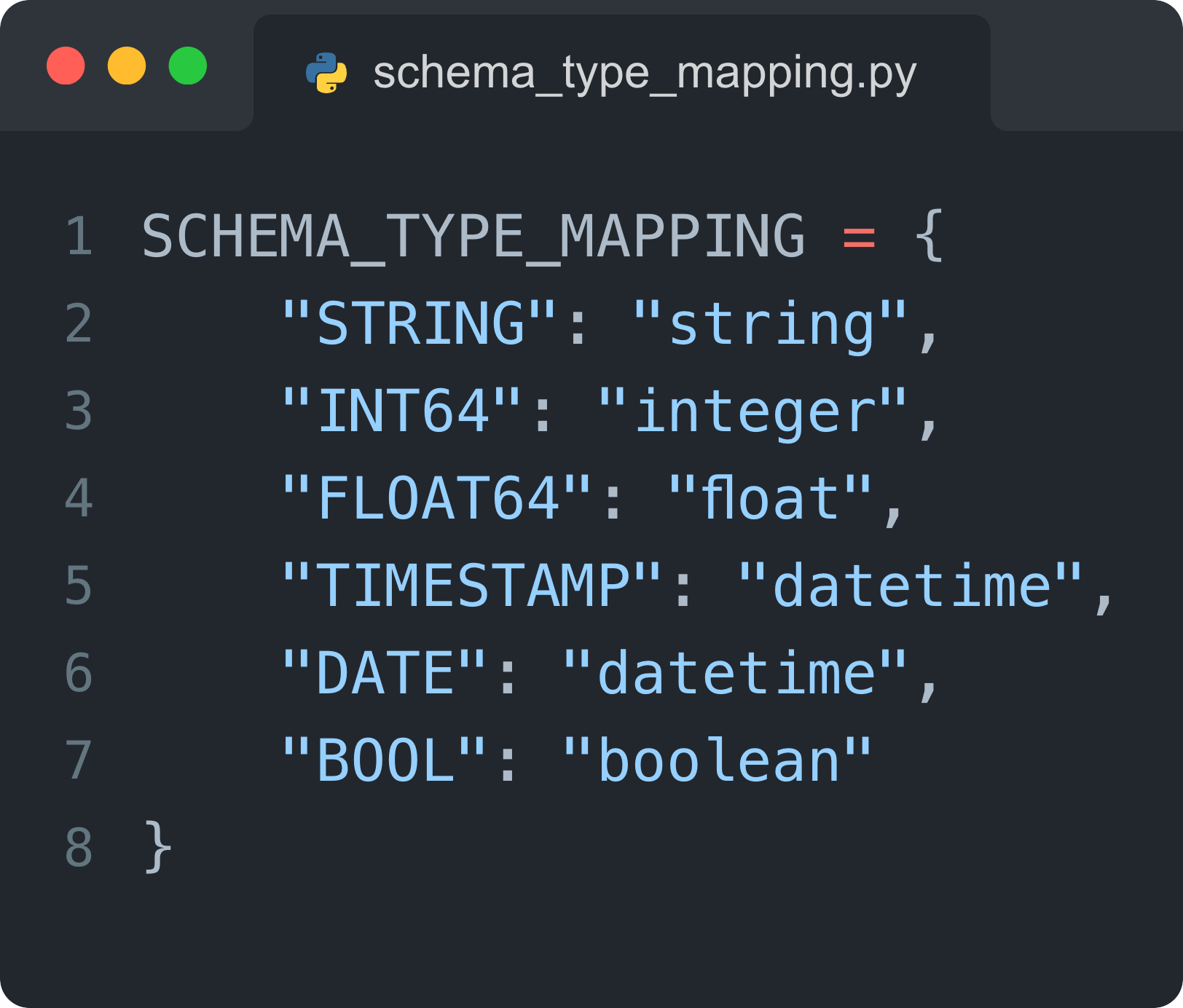
Build a small mapping layer that standardizes your schema into what PandasAI expects.
3. Store your structured schema in YAML
Even if you’re generating your semantic layer dynamically in Python, you’ll want to organize and version it like code. A common folder structure could look like this:
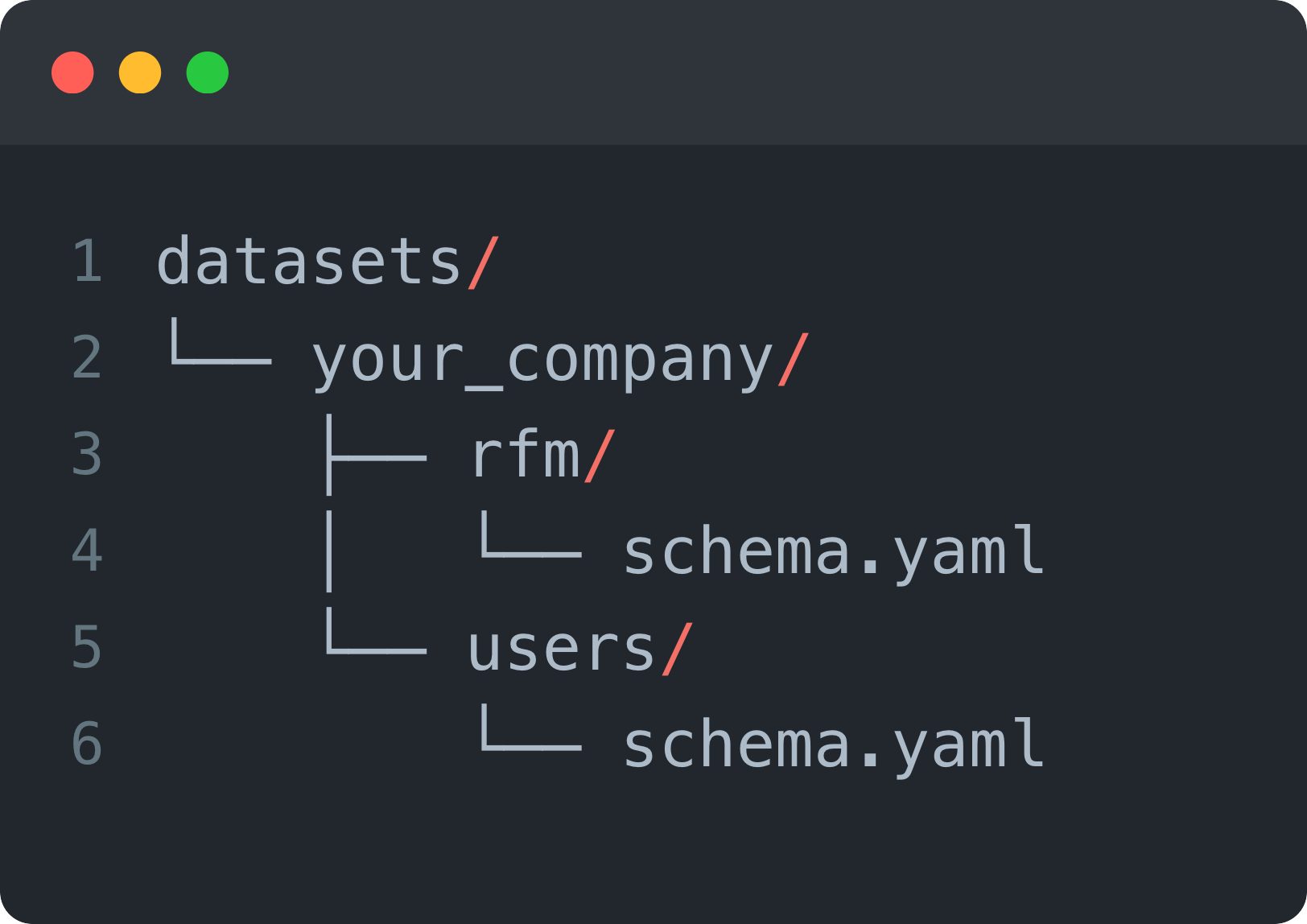
Each schema.yaml should contain your structured version of the raw warehouse schema.
Setting up a clean structure from the very beginning makes it easier to later map your schemas into the format PandasAI expects.
Why this matters
If you're pulling from dozens of tables (which most likely you will), this process should be automated, you don't want to maintain these by hand.
Here is what you want:
Semantic layers that stay in sync with your actual schema
Version-controlled definitions that scale across datasets
A PandasAI setup that feels like part of your production stack, not a side experiment
This is what allows you to use PandasAI reliably across multiple projects, not just for one-off tasks.
Go beyond structure: Guide the logic and make it human-proof
Once your schema is in place, there's one more layer worth adding.
You can define expressions, group-by logic, and column aliases, right inside the same YAML file.
This isn’t just extra metadata.
You’re building in logic that tells PandasAI how to approach common questions:
what to calculate, how to group things, and what names people actually use when referring to the data.
What this might look like in your YAML
Imagine extending your schema.yaml for the RFM dataset:
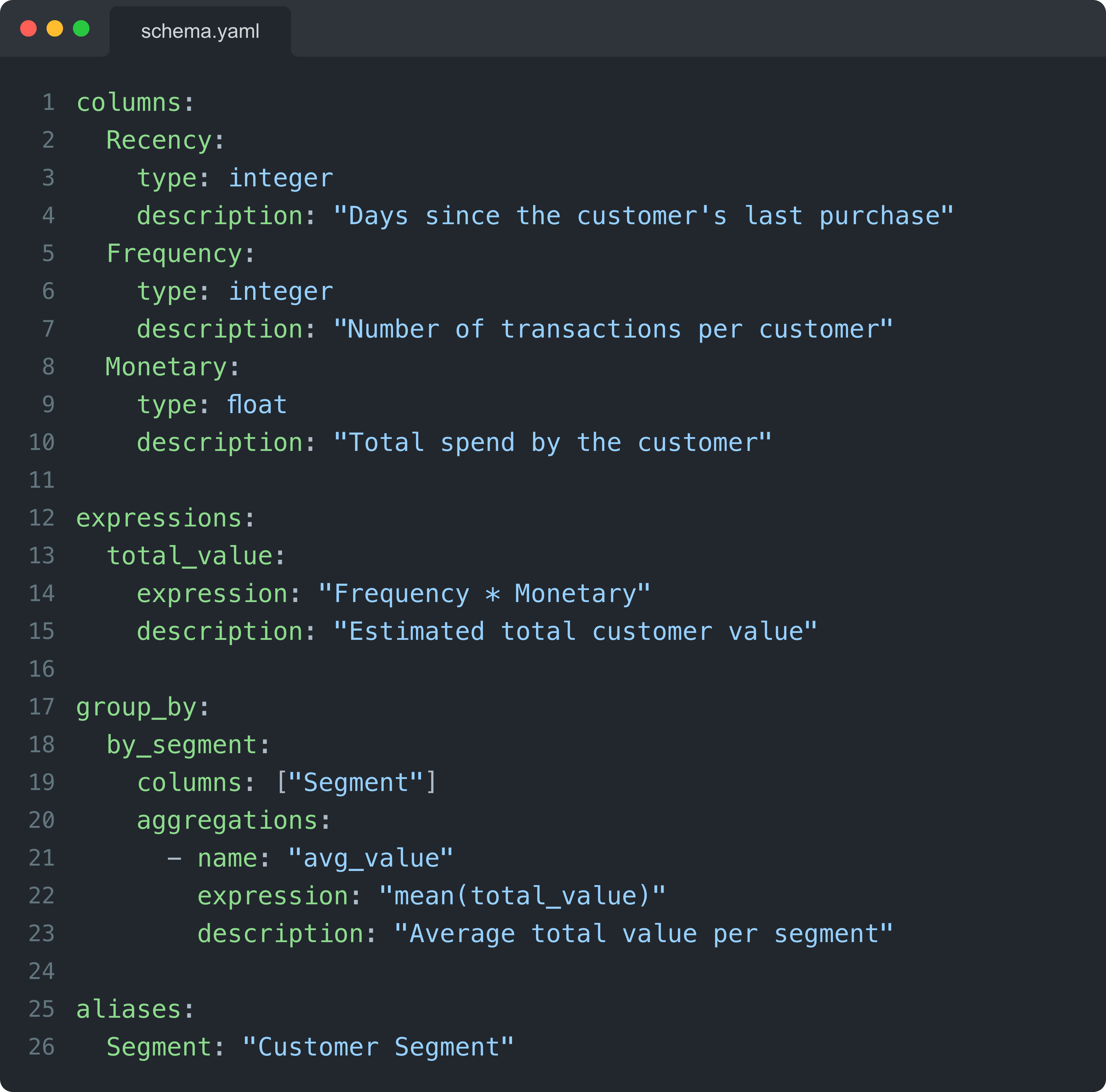
These small additions help your model reason better and make your dataset feel a lot more human to interact with.
💡 There is a lot more you can do on this layer. I highly recommend you check out the documentation on data transformations.
👨💻 Some inspiration
In this short video, I talk about one of the agents I built at work (using PandasAI) to help stakeholders “talk to our data“ and how developing a strong semantic layer unlocked its full potential.
Over the past few months, I’ve started integrating AI more and more into my data science workflows, and I can say with confidence that it has helped me 10x my work.
To help others accomplish the same, I’m launching Future-proof DS.
Future-proof DS is a cohort-based program that teaches you how to use AI to become indispensable at your company, more competitive in the job market, and 10x more effective in your work.
Enrollment for the October 2025 cohort is now open:
Final thoughts
A lot of the hype around LLMs makes it sound like they should just “get it” out of the box, but the truth is, good answers require good structure.
And structure, especially when you’re working with real data, doesn’t just mean columns and types. It also means meaning, logic, and defaults that reflect how your team actually works.
That’s what the semantic layer gives you.
Not just a way to make models smarter, but a way to make your data more aligned with the way people think.
And once you’ve put that in place, you don’t just unlock better outputs. You unlock better questions.
What’s next?
This is not the end of the series.

In Part 3, we’ll explore how PandasAI’s Agent feature lets you embed this context more naturally, so you can handle multi-turn queries, maintain conversational state, and make the entire experience feel more intelligent and fluid.
It’s where the semantic layer really starts to pay off.
A couple of other great resources:
💼 Job searching? Applio helps your resume stand out and land more interviews.
🤖 Struggling to keep up with AI/ML? Neural Pulse is a 5-minute, human-curated newsletter delivering the best in AI, ML, and data science.
🤝 Want to connect? Let’s connect on LinkedIn, I share lots of career bite-sized advice every week.
Thank you for reading! I hope this guide helps you start using PandasAI like a pro (and don’t forget to check out the October 2025 cohort for the “Future Proof DS“ program)
See you next week!
- Andres
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!
An invaluable contribution to the data science community! Thank you!