
Docker For Data Scientists (Part 1): A Gentle Introduction
Your first steps towards deployment

That’s great, but…
This is the reaction every stakeholder has after you announce you built yet another great ML model, but there are no plans to move it out of its Jupyter notebook.
They are dying for you to answer, “How can I actually use it in my day-to-day?“
The future of data science isn’t just in building models or running analyses. It is in making sure your work can be reproduced and actually used by others:
If your notebook only runs on your laptop, it does not create a lasting impact.
If your model cannot be shared, it never reaches its potential.
As the field continues to move from individual experiments to collaborative projects and production systems, these challenges matter more than ever.
Reproducibility and accessibility are no longer nice-to-haves. They are the foundation of professional data science.
This is where Docker comes in. It gives you a way to package your work so it runs the same everywhere and can be shared without the usual dependency headaches.
So if you give me 5 minutes, I promise to get you started using Docker.
Here’s what we’ll cover:
Why Docker matters for Data Science
Docker Images vs. Containers
Dockerfile basics
🎥 Docker in action demo
Why Docker matters for Data Science
In data science, two challenges come up again and again:
Reproducibility: making sure your code runs the same way today, tomorrow, and on someone else’s machine.
Accessibility: making your work usable by others, whether that is a stakeholder opening a dashboard or a teammate testing your model.
Docker tackles both.
By packaging your environment into a container, you avoid the dependency issues and version conflicts that often break projects. Once your work is in a container, it is no longer tied to your setup. It can be shared, deployed, or scaled without worrying about the hidden details of your machine.
Here are three examples that show what this looks like in practice:
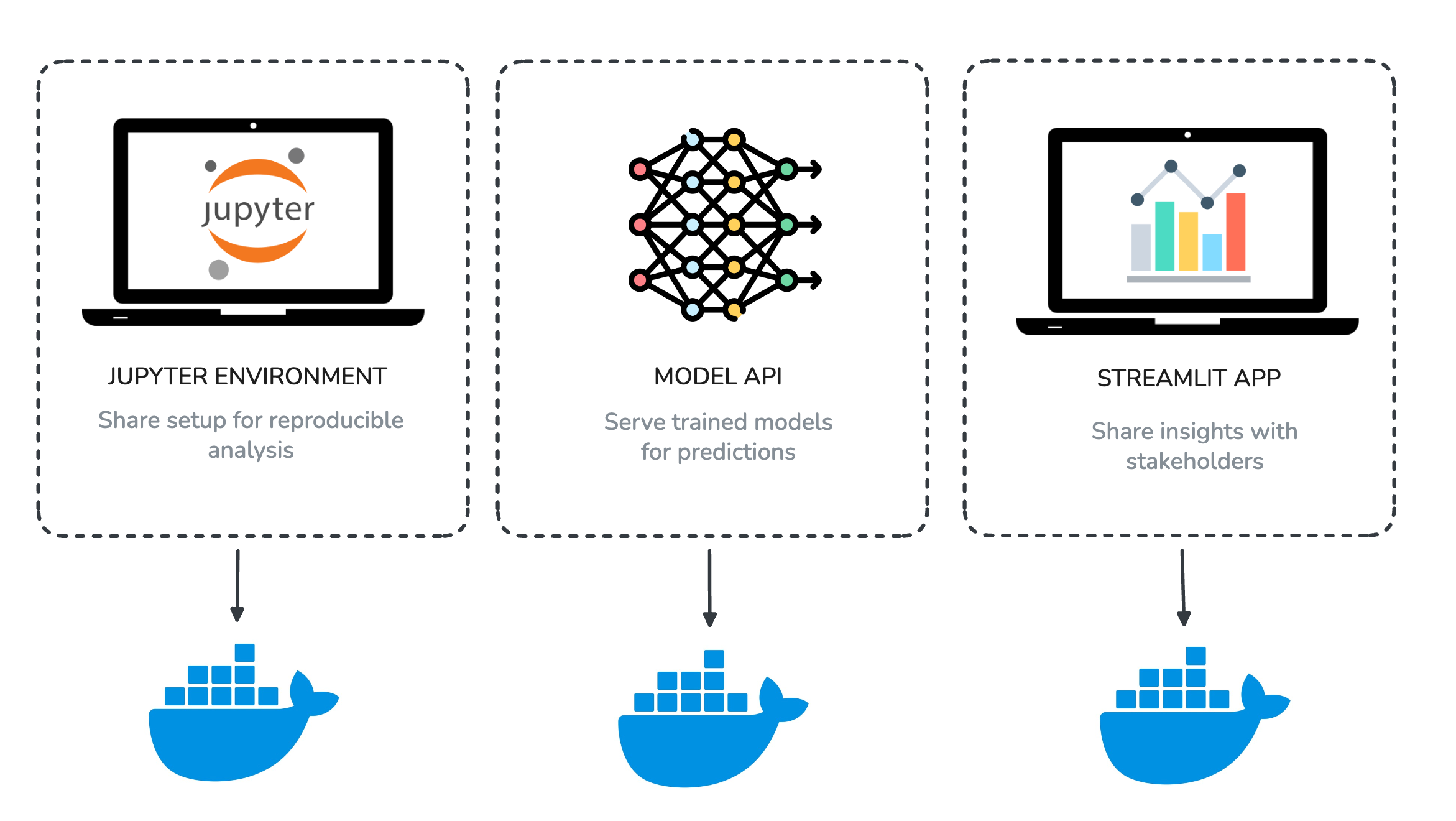
Jupyter Notebook Environment
Spin up a ready-to-use JupyterLab with Python and all your favorite libraries pre-installed. Instead of fighting with conda or pip, you and your teammates can share the same reproducible setup with one command.
Machine Learning Model API
Package a trained ML model (like a churn predictor or recommendation engine) inside a Flask or FastAPI container and expose it as an API. This makes your model available for real-time predictions that other apps, dashboards, or teammates can call directly.
Streamlit Dashboard
Wrap your Streamlit app inside Docker so it can be deployed anywhere with zero setup. Great for sharing interactive dashboards or prototypes with stakeholders without worrying about their local Python setup.
Docker Images vs. Containers
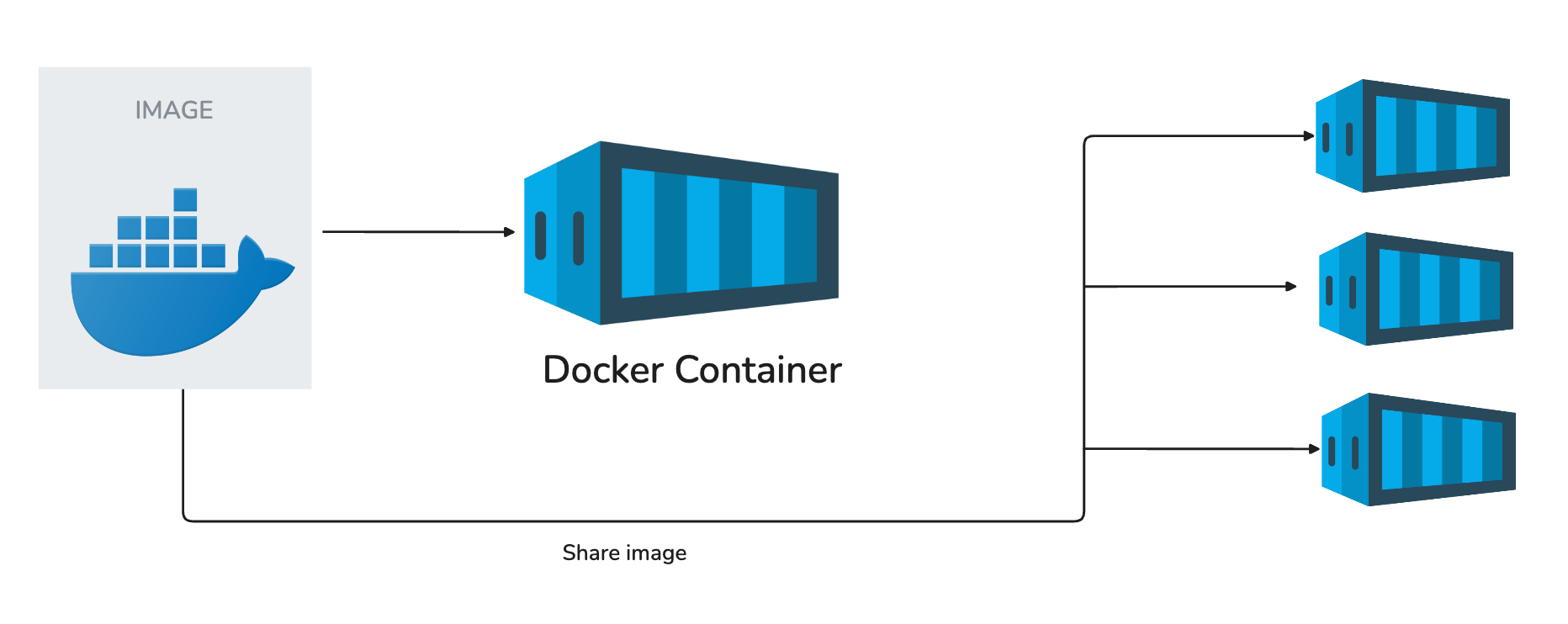
A common source of confusion when learning Docker is the difference between an image and a container.
Think of it like this:
An image is a blueprint. It defines everything your project needs, such as code, libraries, and environment setup, but it does not run by itself.
A container is a running instance of that blueprint. It is what you can actually interact with, stop, or restart.
In practice, you only need to build an image once, and you can run as many containers as you want from that image
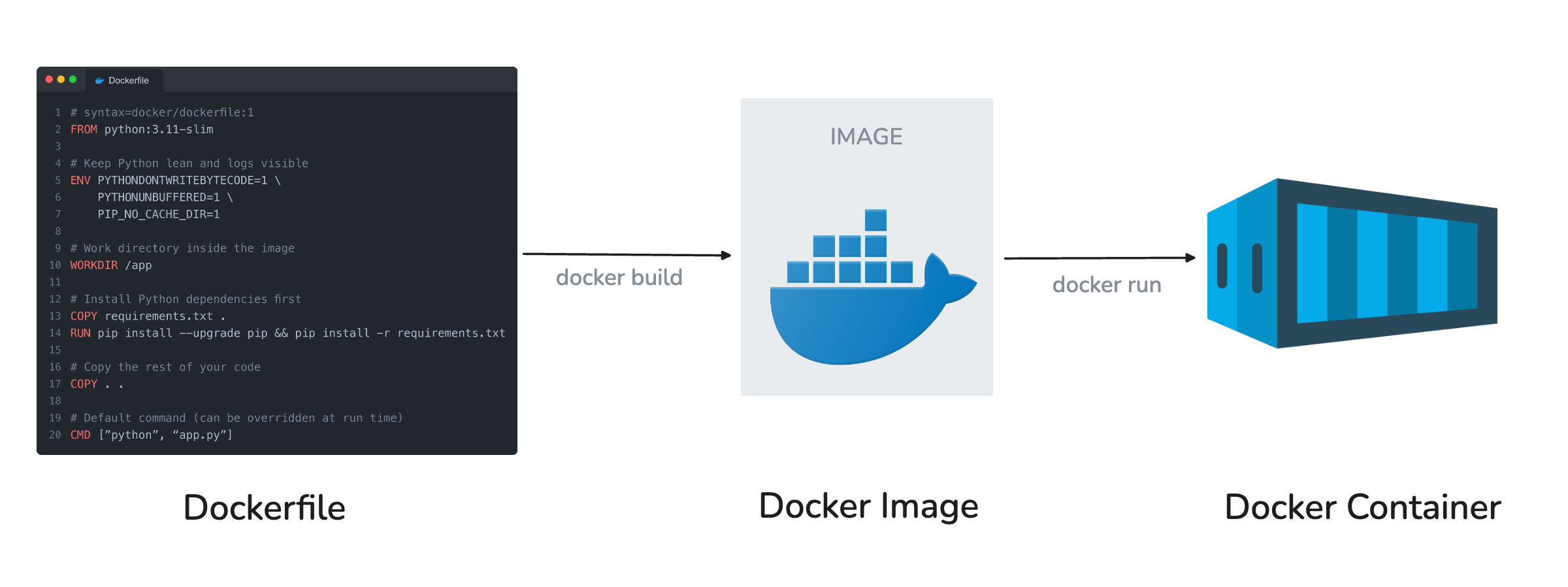
Dockerfile basics
A Dockerfile is the recipe that builds your image.
Once you have an image, you can start containers that run your work the same way on any machine.
1. Project setup
Your Dockerfile goes in the project, usually in the root directory
project/
app.py
requirements.txt
Dockerfile2. Write your Dockerfile
Here is a template you can start from:
What each line means:
FROM: chooses the base image (a lightweight Python in this case).
ENV: sets flags that reduce clutter and keep logs visible.
WORKDIR: defines the working directory inside the image.
COPY requirements.txt + RUN pip install: installs dependencies in a cacheable layer.
COPY . .: copies your project files.
CMD: tells Docker what to run when the container starts.
4. Build the image
From the project root, run:
docker build -t my-app:latest .5. Start a container
Run your app with:
docker run --rm my-app:latestIf your app serves HTTP, map a port:
docker run --rm -p 8000:8000 my-app:latest🎥 Quick demo
Here is a quick walk-through of how to build a Docker image and run a container:
💡 Pro tip: Add a .dockerignore file
Keep builds fast and images small by creating a .dockerignore file in your project.
This file tells Docker which files and folders to skip when copying your code into the image. Without it, everything in your project directory is included by default, which can bloat your image with things like cached files, large datasets, virtual environments, or even your entire .git history.
A good starting point:
__pycache__/
*.pyc
*.ipynb_checkpoints
.env
.venv/
.git/
data/This way, your image contains only what it actually needs to run, nothing more. It speeds up the build process, keeps images lighter, and avoids leaking sensitive or irrelevant files.
Wrapping Up
By now, you’ve seen how Docker helps with the two things data scientists often struggle with most: making work reproducible and making it accessible.
We looked at real examples where Docker fits into everyday projects, cleared up the difference between images and containers, and built a foundation with the Dockerfile.
This is enough to get you started, but it’s only the beginning.
In Part 2, we’ll go a step further:
Docker compose files
Layer caching
Sharing images on Dockerhub and more
A couple of other great resources:
🚀 Ready to take the next step? Build real AI workflows and sharpen the skills that keep data scientists ahead.
💼 Job searching? Applio helps your resume stand out and land more interviews.
🤖 Struggling to keep up with AI/ML? Neural Pulse is a 5-minute, human-curated newsletter delivering the best in AI, ML, and data science.
Thank you for reading! I hope this guide helps you start deploying your projects.
See you next week!
- Andres
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!
Loved this! I was introduced to Docker about 6 years ago during an internship and was teaching myself what everything meant...what a struggle. I could've used this intro then. Very clear instructions and definitions.
Very clear instructions! Thank you!