
6 Research Papers Every Data Scientist Should Read In 2026
How far AI agents will automate data science, machine learning research, and broad scientific discovery

Scroll through social media for a few minutes, and you’ll be bombarded with posts about the latest AI tool and how much it is “disrupting” the field. But very little is being said about what is actually happening in research.
The focus there is not on tools, but on frameworks and end-to-end systems.
And that’s where the real signal is.
If you want to understand how far AI could transform how we do data science over the next few years, you need to look at the direction these systems are heading.
So I’ve gathered 6 research papers covering recent advances in autonomous AI agents designed to automate data science, machine learning research, and even broader scientific discovery.
At the end, I also share my take on what this actually means for us today and how we should prepare.
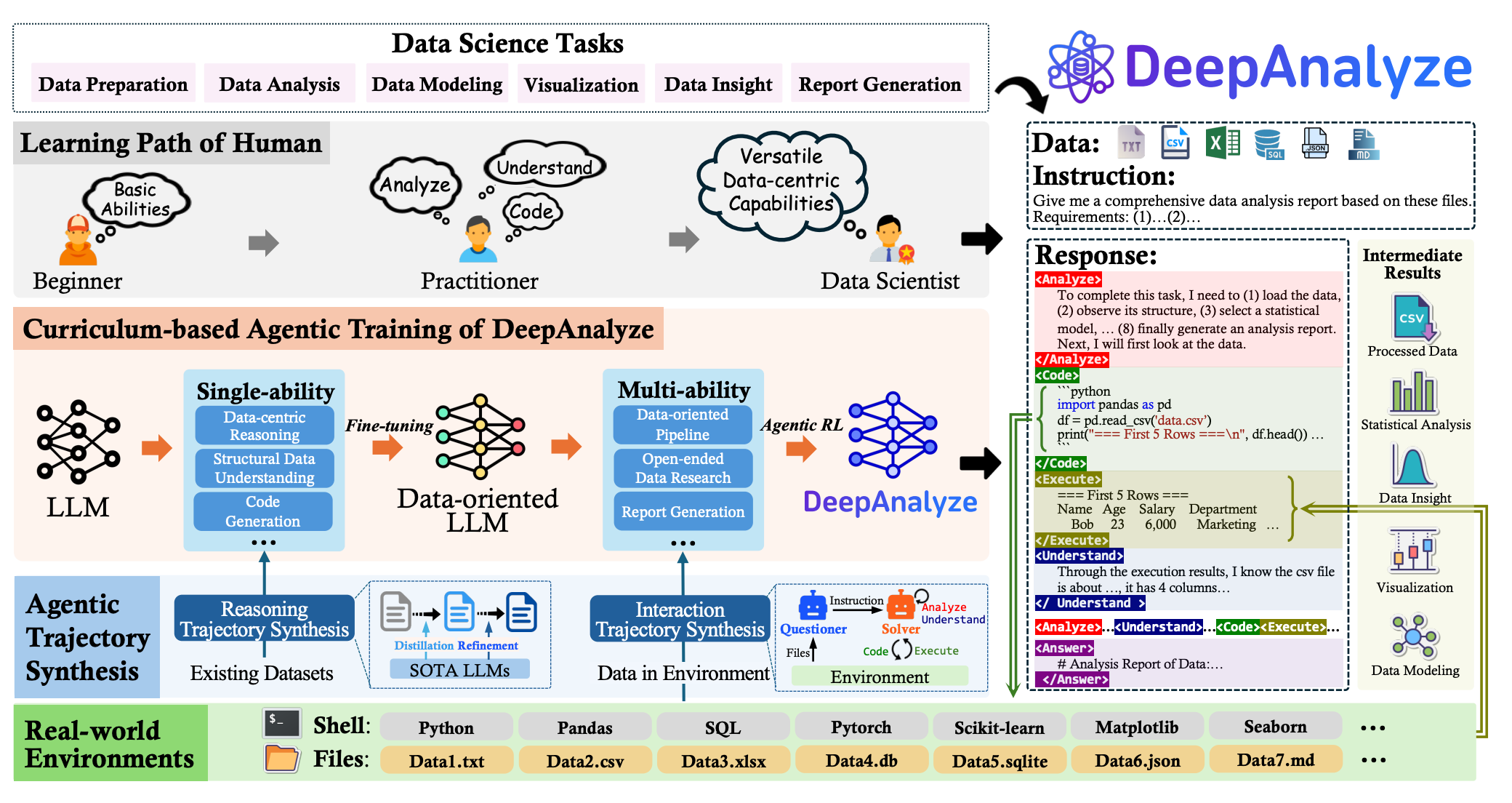
1. DeepAnalyze: Autonomous Data Science via Agentic LLMs
This research paper introduces DeepAnalyze-8B, an agentic model trained to autonomously handle the entire data science pipeline from raw data to professional research reports. It uses a curriculum-based training paradigm to acquire complex problem-solving capabilities similar to those of a human data scientist.
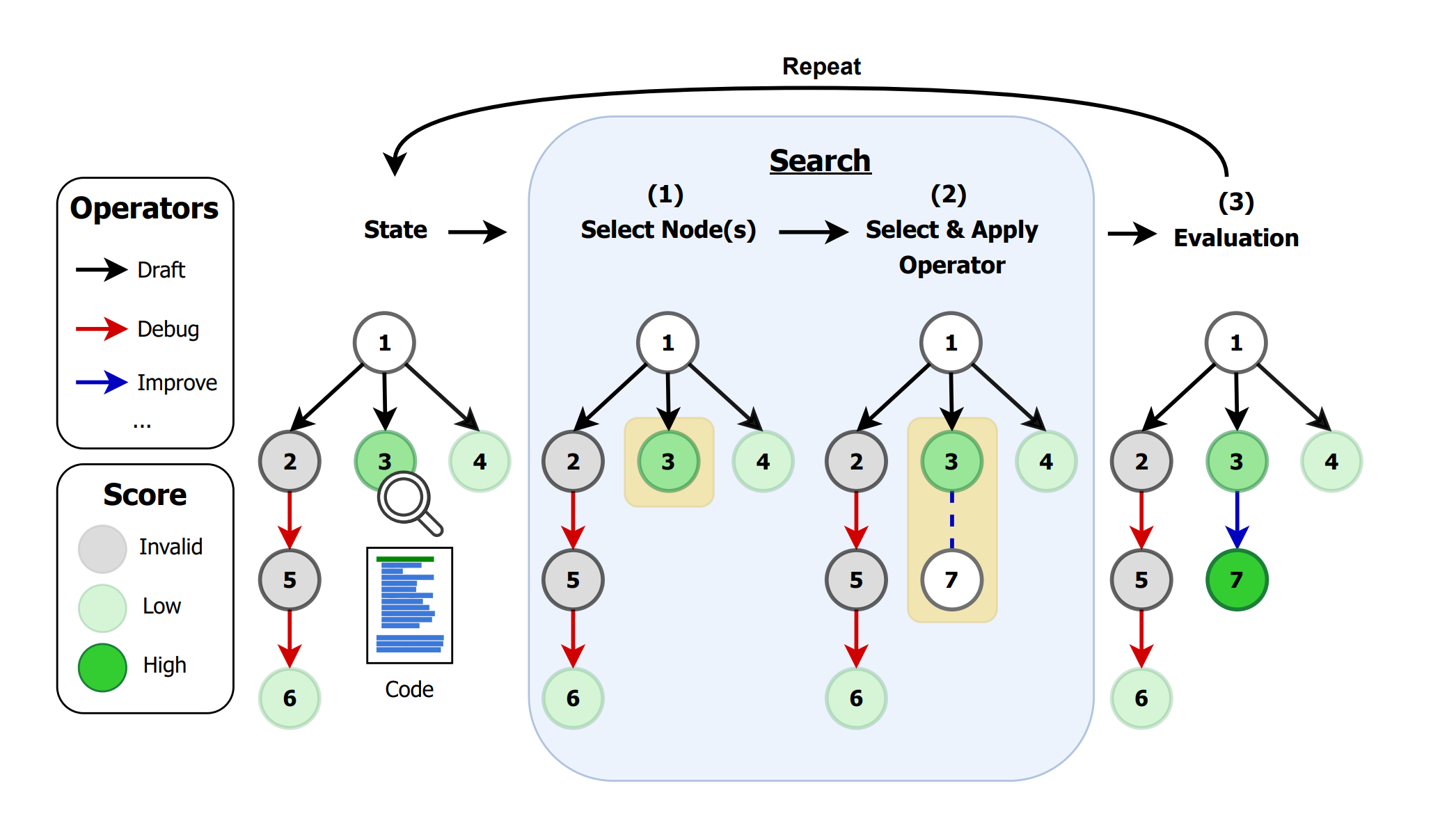
2. AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
This paper studies AI agents that compete in Kaggle competitions by exploring solution spaces using search strategies like Monte Carlo Tree Search and evolutionary methods. The study shows that pairing these search policies with well-designed operators significantly improves performance in real ML engineering tasks.
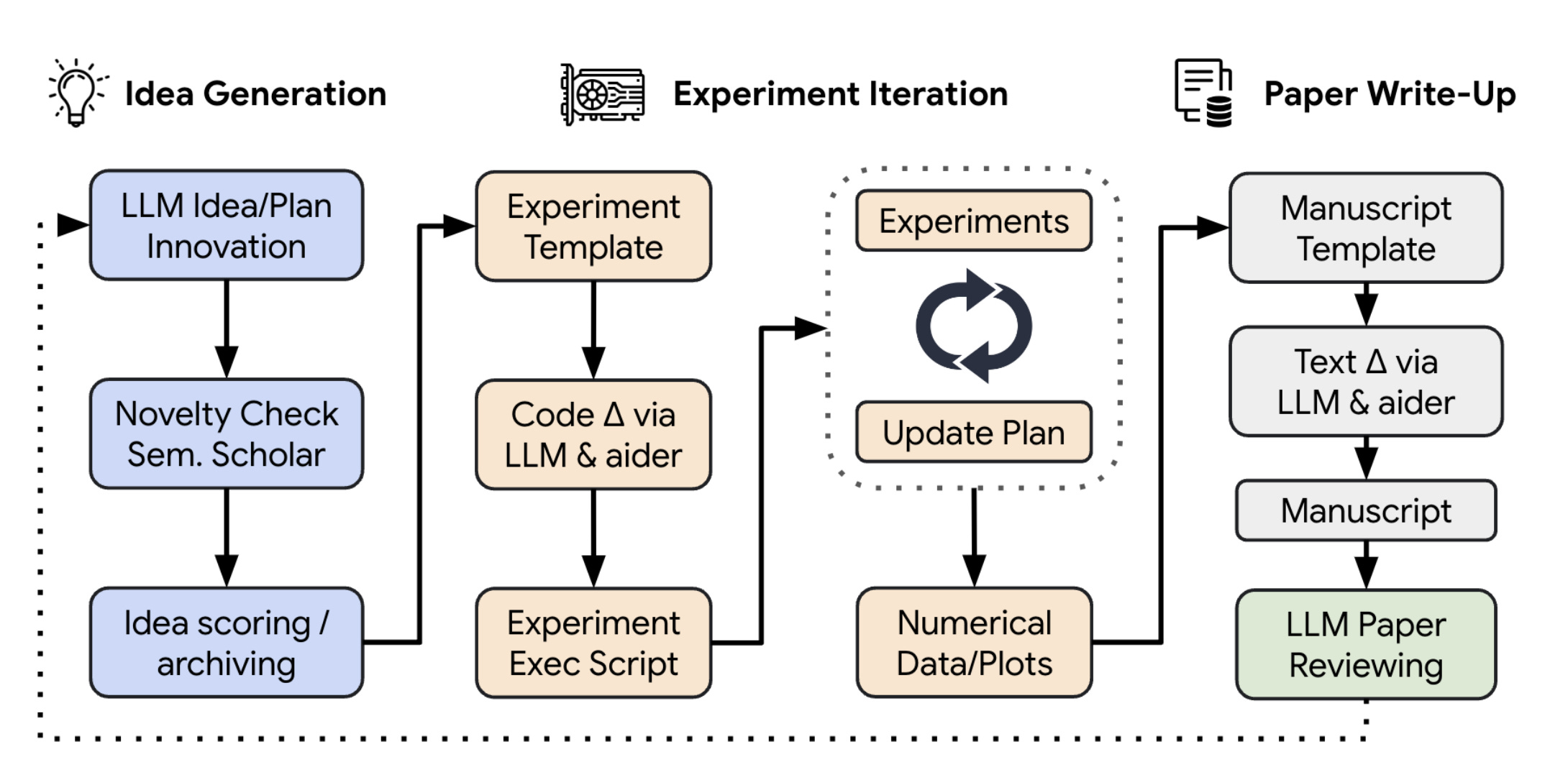
3. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
This paper introduces an autonomous framework that can perform the entire ML research lifecycle: generating ideas, running experiments, analyzing results, and writing full research papers. It even includes an automated LLM-based peer-review system to evaluate the generated work.
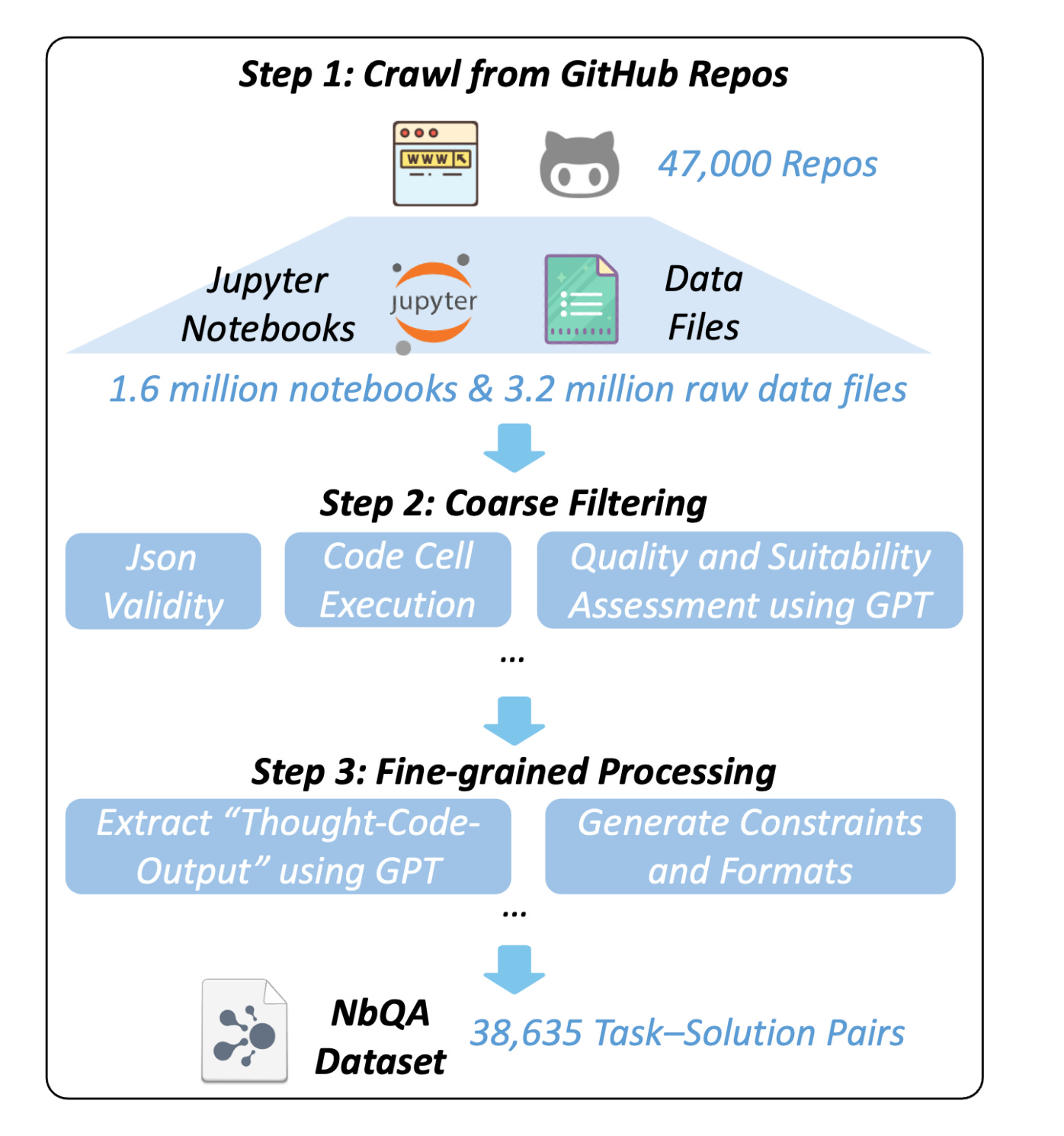
4. Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
This paper introduces NbQA, a large dataset of real Jupyter notebook analysis tasks, and JUPITER, a framework that treats notebook-based data analysis as a sequential decision-making search problem. A value model guides the reasoning process to efficiently solve multi-step data analysis tasks.
5. DS-STAR: A state-of-the-art versatile data science agent
This paper by Google proposes an agentic system designed to handle real-world data science workflows involving heterogeneous data sources such as CSV, JSON, and text. It decomposes analysis into sub-questions and iteratively builds evidence-based reports to minimize hallucinations.
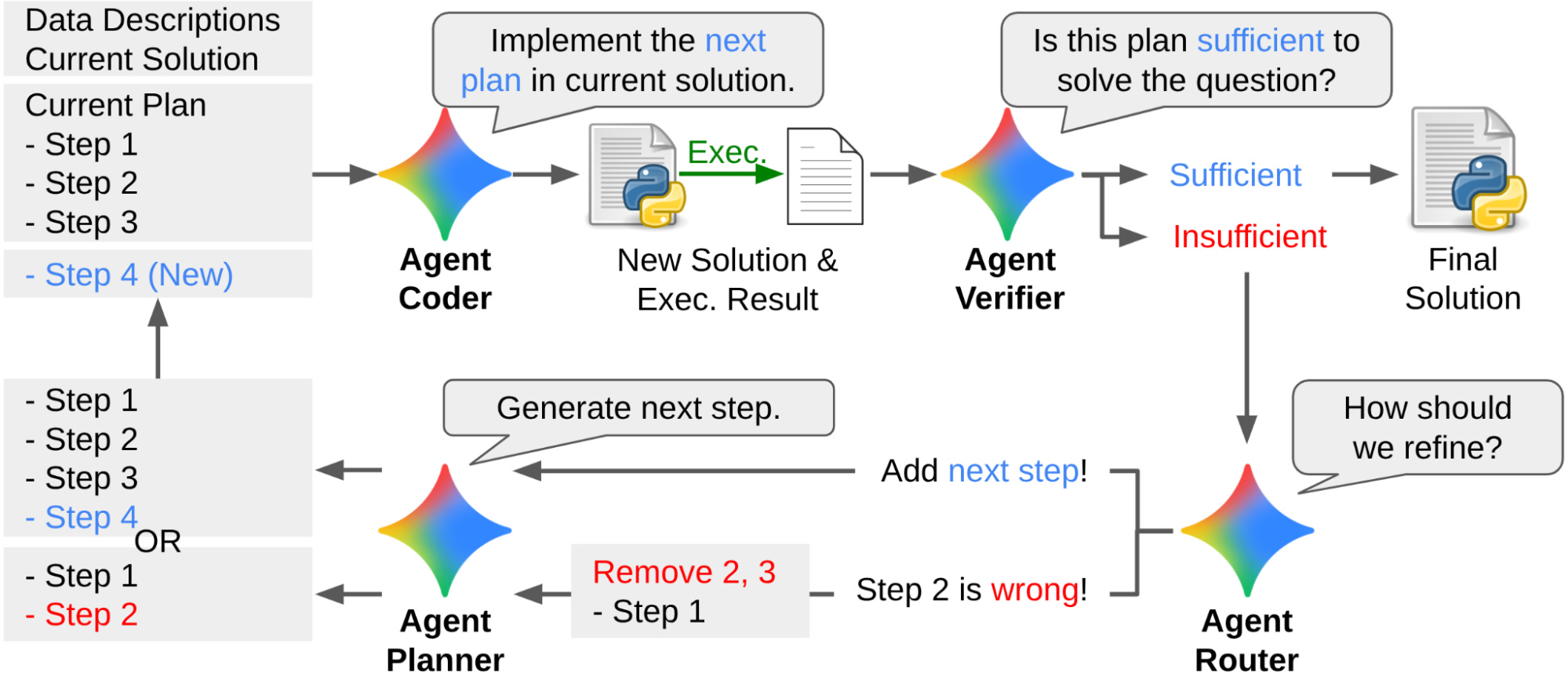
6. Kosmos: An AI Scientist for Autonomous Discovery
This paper presents a scientific discovery agent that coordinates literature search and data analysis through a structured world model. By running long autonomous research loops, it can read thousands of papers and execute large-scale experiments to generate traceable scientific discoveries.
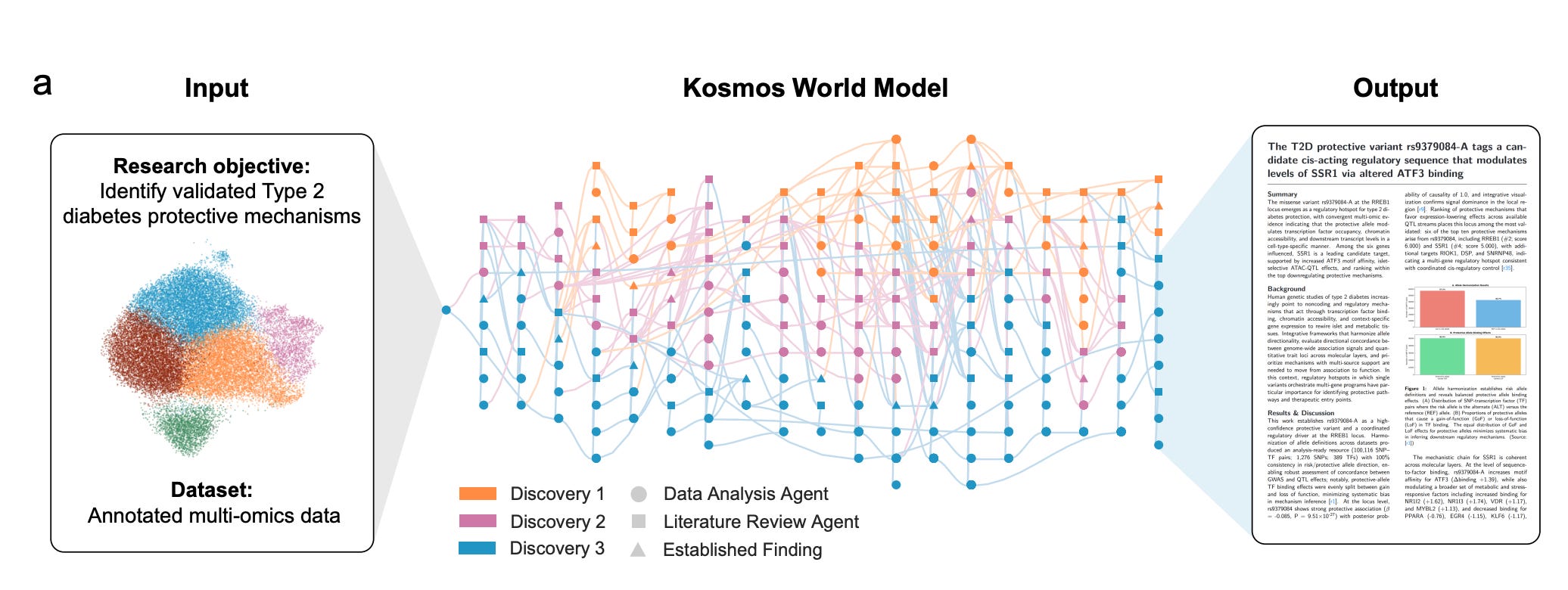
The common denominator
Across these papers, one thing becomes clear: we are moving from AI as a tool to systems that can operate across the entire data science lifecycle. Not just assisting with isolated tasks, but handling the full loop, from defining problems to running analyses and producing research-level outputs.
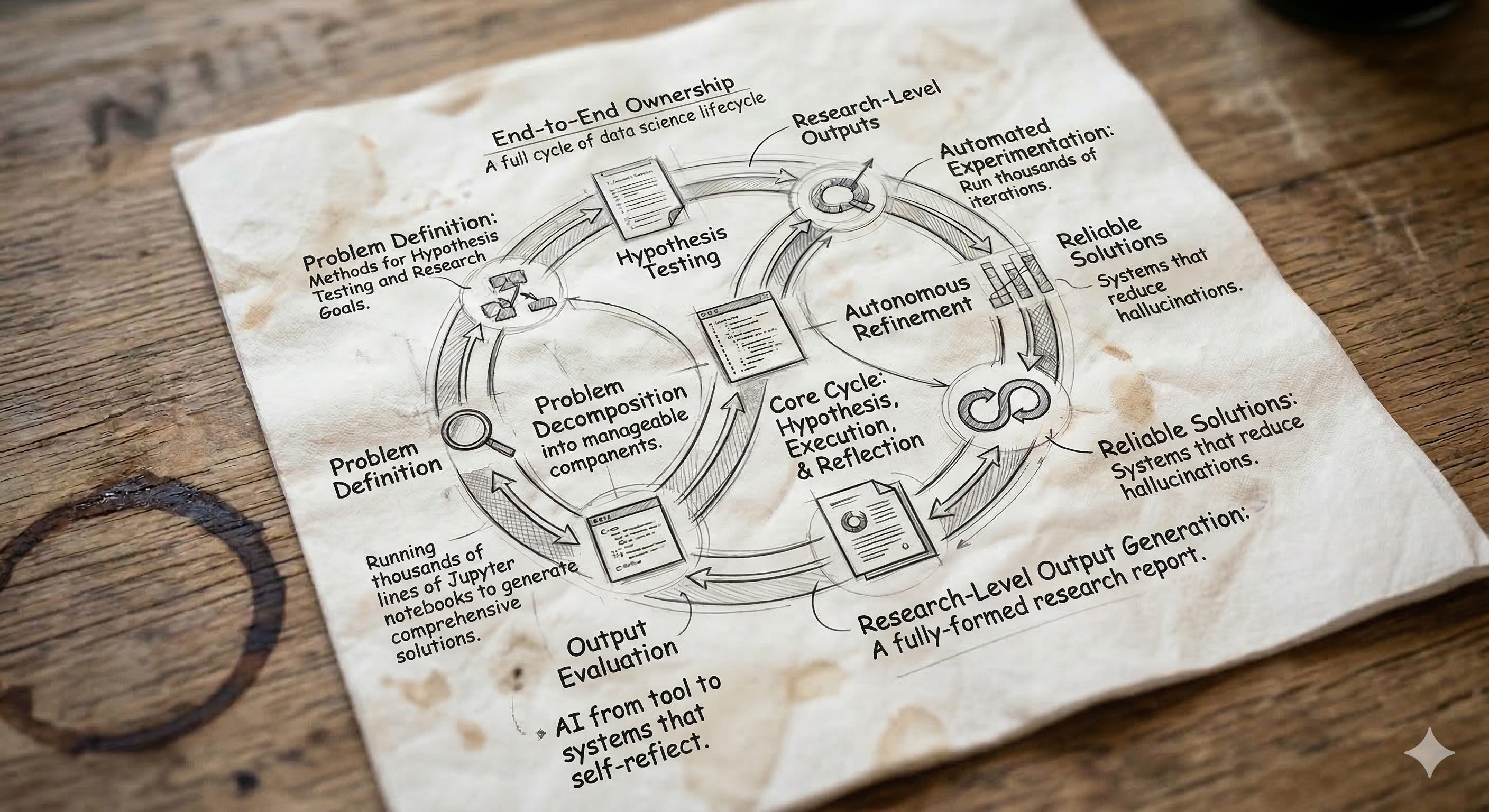
A big part of this shift comes from how these systems are designed. They don’t rely on a single pass. Instead, they iterate. Through feedback loops, search strategies, and self-reflection, they refine their outputs step by step, getting closer to something that actually resembles how a data scientist would approach a problem.
When you combine this with large-scale training data, like real Jupyter notebooks, and more structured ways of interacting with data and external knowledge, the result is systems that can reproduce fairly complex reasoning.
There are a few patterns that show up consistently across these papers:
End-to-end ownership: These systems don’t just assist, they handle the full workflow, from ideation to final output.
Iterative refinement: Instead of one-shot answers, they rely on loops, evaluation, and correction.
Decomposition of problems: Open-ended questions are broken down into smaller, verifiable steps grounded in data, code, or literature.
Built-in evaluation: With automated reviewing and benchmarks, they can critique and improve their own outputs.
Another important shift is reliability. By grounding their reasoning in executable steps and verifiable sources, these systems start to reduce one of the biggest limitations we’ve seen so far: hallucinations in open-ended tasks.
Put together, this starts to look less like a model you prompt, and more like a system that can iterate on its own work, explore a space of ideas, and converge toward something useful.
My honest take
When I shared these papers on my LinkedIn, I got a comment that stood out.
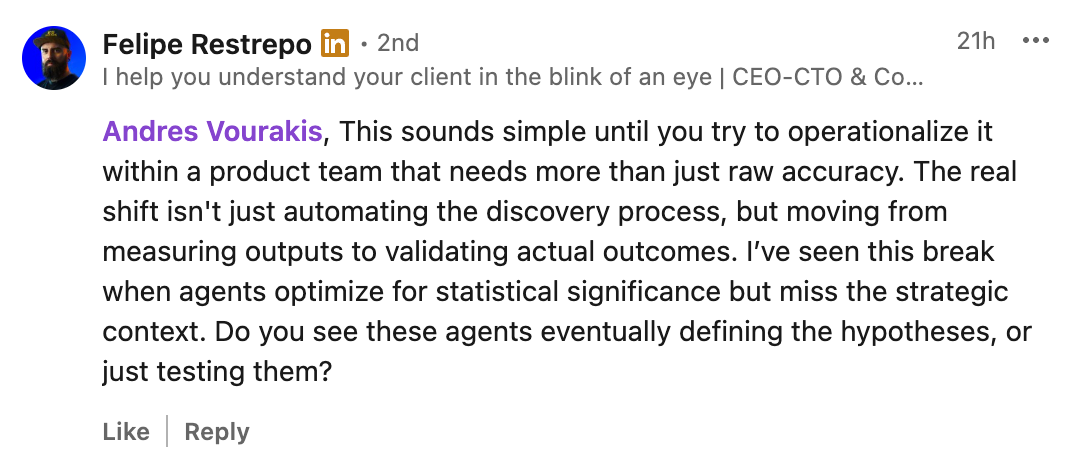
Because, regardless of how far these frameworks go in automating the analysis process, the question remains the same:
Can they actually operate under real-world constraints, in companies where more than accuracy matters, and where business context is far more nuanced than what can fit into a few documentation pages?
For the foreseeable future, I still see a strong need for a human-in-the-loop, regardless of how capable these models become or how large their context windows get (and by the way, Claude just made their 1M context window widely available for their latest models).
Still, the limiting factor isn’t intelligence, it’s context.
And more specifically, how that context is structured, injected, and continuously updated. In practice, a large part of what drives good analysis is not explicitly written down. It lives in things like:
Shifting priorities across teams
Implicit assumptions behind metrics and decisions
Trade-offs that only emerge through experience and stakeholder context
This is the layer that doesn’t neatly fit into prompts or documentation.
That said, I do think there are specific environments where these agents will start defining and evaluating their own hypotheses. In well-scoped problems, with reliable data and clear feedback signals, they have a clear advantage. They can explore a much larger hypothesis space and validate ideas at a speed that is simply not possible for a human.
Where this becomes powerful is in narrowing the gap between exploration and validation, not by removing the human, but by making it possible to test more ideas, faster, without losing control over what actually matters.
A couple of other great resources:
🚀 Ready to take the next step? Build real AI workflows and sharpen the skills that keep data scientists ahead.
🤖 Struggling to keep up with AI/ML? Neural Pulse is a 5-minute, human-curated newsletter delivering the best in AI, ML, and data science.
Thank you for reading! I hope this breakdown gives you a glimpse into the future of data science.
- Andres Vourakis
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!
Thanks for sharing. Six papers help validate our own system.